How did people with different social identities experience the congress?
7.1 Discrimination and harassment
Respondents of the post-congress survey were asked if they themselves experienced discrimination and/or harassment (of any sort) at the congress and whether they reported it to the Awareness team, or if they witnessed someone else experiencing this.
A total of 11 respondents experienced some form of discrimination or harassment, of which 2 cases were reported to the Awareness team. A total of 3 respondents witnessed somebody else receiving some form of discrimination or harassment, of which 1 case was reported to the Awareness team. Reasons of not reporting the cases to the Awareness team included that the case was unrelated to EDI issues. Even though only a few cases were reported to the Awareness team, the qualitative feedback given in the survey highlighted that the presence of this team made some people feel safe.
Due to the low number of reports of discrimination or harassment, we cannot statistically test if some social identities experienced more discrimination/harassment than others. Nevertheless, these are the summary statistics per social identity for the answer to whether respondents experienced discrimination/harassment themselves:
, , = West Europe
No Yes
Female 3 3
Male 1 0
Non-binary 0 0
, , = North Europe
No Yes
Female 0 1
Male 0 0
Non-binary 0 0
, , = South Europe
No Yes
Female 0 0
Male 0 0
Non-binary 0 0
, , = East Europe
No Yes
Female 0 0
Male 0 0
Non-binary 0 0
, , = North America
No Yes
Female 1 0
Male 0 0
Non-binary 0 1
, , = Oceania
No Yes
Female 0 0
Male 0 0
Non-binary 0 0
, , = South American
No Yes
Female 0 0
Male 0 0
Non-binary 0 0
, , = Asia
No Yes
Female 0 0
Male 0 0
Non-binary 0 0
, , = Dual-nationality
No Yes
Female 0 0
Male 0 0
Non-binary 0 0
This shows that most reports came from women, and from West Europe.
7.2 Congress experience
In the post-congress survey, we asked respondents to answer on a 7-point Likert scale (1: Strongly disagree, 7: Strongly agree) how much they agree with the following three statements: 1) “I felt heard during the conversations I had, both during Q&A sessions and social activities”; 2) “I felt comfortable being myself”; 3) “Attending the Behaviour 2023 congress helped me feel like I belong in my research field”. For each of the three statements, we fitted ordinal GLMs to identify which social identity variables (gender, LGBTQIA+, nationality, affiliation, expat status) were significantly associated with the Likert-scale response to the statement. Additionally, we controlled for the level of comfort a person had speaking English as well as their self-reported level of expertise. Only the variables that were significant were used in the final model.
We have information on three variables that roughly measure the same thing: age is indicative of career stage, career stage is indicative of expertise, and self-reported expertise rating directly measures this expertise. Since age and career stage are indicator variables of expertise, we therefore only investigate expertise rating as this will give us the signal we are interested in.
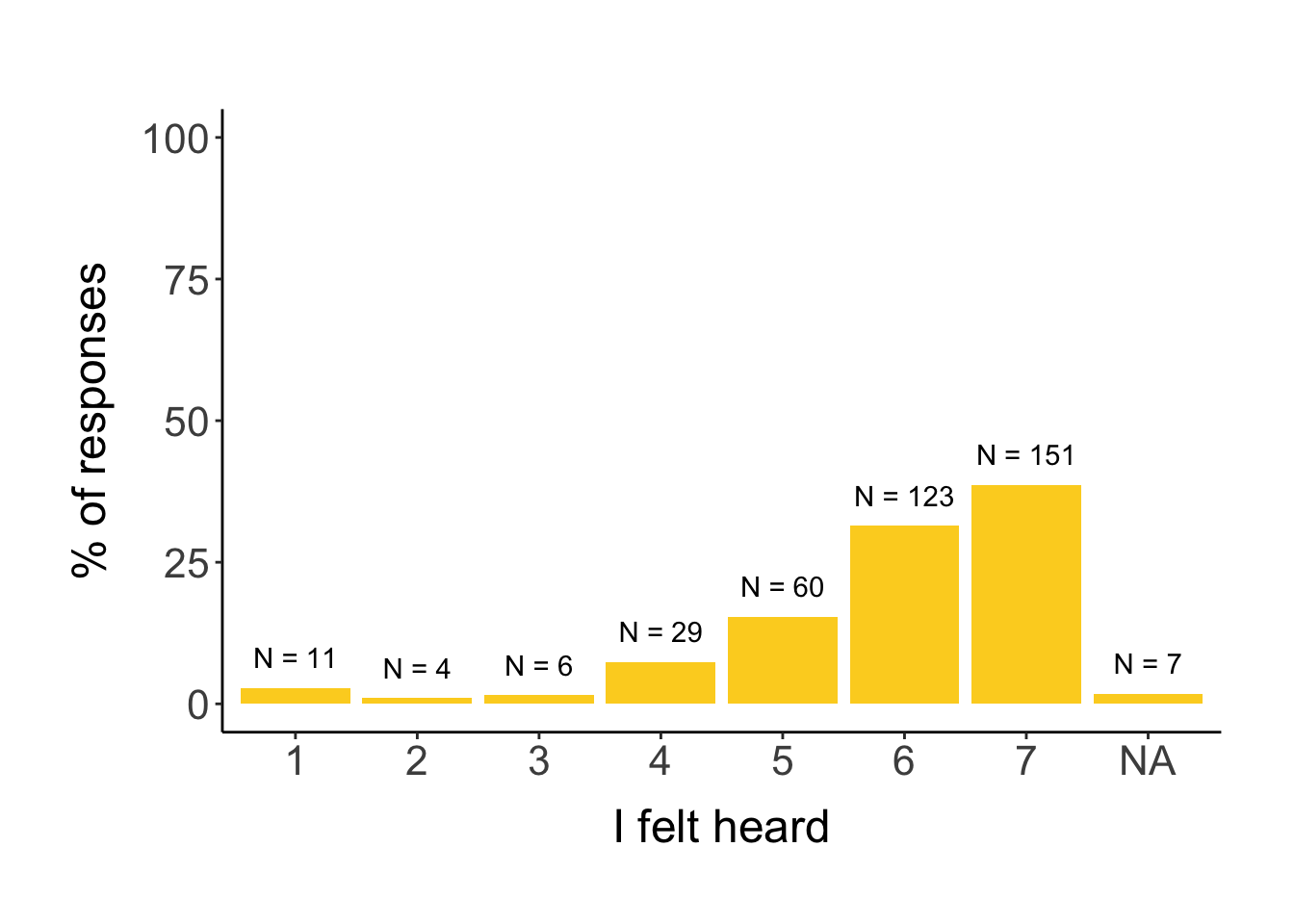
7.2.1 Feeling heard
# first, we explore the distribution of answers# feeling heardggplot(survey, aes(feeling_heard_rating)) +geom_histogram(stat="count", aes(y=stat(count/sum(count)*100)), fill = clrs[11]) +geom_text(aes(label =paste0("N = ", ..count..), y =stat(count/sum(count)*100)), stat="count", vjust=-1) +ylim(0, 100) +labs(x ="I felt heard", y ="% of responses")
# next: explore the relationship between age and expertise, and career stage and expertise ratingcoeftest(polr(as.factor(expertise_rating) ~ age, data = survey))
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
age35-50 2.02180 0.22656 8.9239 < 2.2e-16 ***
age> 50 3.43812 0.38098 9.0244 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
coeftest(polr(as.factor(expertise_rating) ~ career_3cat, data = survey))
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
career_3catMid 2.20513 0.23164 9.5196 < 2.2e-16 ***
career_3catLate 4.16000 0.36819 11.2985 < 2.2e-16 ***
career_3catOther 1.81962 0.53727 3.3868 0.0007817 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# as expected!# another check: is expertise rating affected by gender?coeftest(polr(as.factor(expertise_rating) ~ gender, data = survey))
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
genderMale 0.074149 0.203076 0.3651 0.7152
genderNon-binary -0.208320 0.759624 -0.2742 0.7841
# answer = no# then we test the effect of each of the social identity variables# gendersurvey$gender <-factor(survey$gender, levels =c("Male", "Female", "Non-binary"))m_heard_gender_null <-polr(feeling_heard_rating ~1, data=subset(survey, !is.na(gender)))m_heard_gender <-polr(feeling_heard_rating ~ gender,data=survey) m_heard_gender_out <-collect_out(model = m_heard_gender, null = m_heard_gender_null, name ="feeling_heard_gender", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_heard_gender_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
feeling_heard_gender
AIC
1086.637
n_obs
373
lrt_pval
0.112
lrt_chisq
4.378
intercept_12
-3.623
intercept_23
-3.302
intercept_34
-2.95
intercept_45
-1.997
intercept_56
-1.001
intercept_67
0.355
n_factors
2
est_genderFemale
-0.113
lowerCI_genderFemale
-0.525
higherCI_genderFemale
0.3
se_genderFemale
0.21
tval_genderFemale
-0.537
pval_genderFemale
0.591
est_genderNon-binary
-1.348
lowerCI_genderNon-binary
-2.576
higherCI_genderNon-binary
-0.12
se_genderNon-binary
0.624
tval_genderNon-binary
-2.158
pval_genderNon-binary
0.032
# lgbtqia m_heard_lgbtq_null <-polr(feeling_heard_rating ~1, data=subset(survey, !is.na(lgbtq)))m_heard_lgbtq <-polr(feeling_heard_rating ~ lgbtq,data=subset(survey, !is.na(lgbtq))) m_heard_lgbtq_out <-collect_out(model = m_heard_lgbtq, null = m_heard_lgbtq_null, name ="feeling_heard_lgbtq", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_heard_lgbtq_out %>%t() %>%kbl() %>%kable_classic_2() # almost significant, note that the baseline is answer "No" to lgbtq identity
model_name
feeling_heard_lgbtq
AIC
1049.062
n_obs
360
lrt_pval
0.059
lrt_chisq
3.567
intercept_12
-3.658
intercept_23
-3.31
intercept_34
-2.935
intercept_45
-1.968
intercept_56
-0.946
intercept_67
0.353
n_factors
1
est_lgbtqYes
-0.487
lowerCI_lgbtqYes
-0.992
higherCI_lgbtqYes
0.018
se_lgbtqYes
0.257
tval_lgbtqYes
-1.895
pval_lgbtqYes
0.059
# nationalitysurvey$nationality_continent <-factor(survey$nationality_continent, levels =c("Europe", "Asia", "North America", "Oceania", "South America"))m_heard_nat_null <-polr(feeling_heard_rating ~1, data=subset(survey, !is.na(nationality_continent)))m_heard_nat <-polr(feeling_heard_rating ~ nationality_continent,data=survey) m_heard_nat_out <-collect_out(model = m_heard_nat, null = m_heard_nat_null, name ="feeling_heard_nat", n_factors =4, type ="likert", save ="yes", dir ="../results/survey") m_heard_nat_out %>%t() %>%kbl() %>%kable_classic_2() # almost significant, but Asia is borderline sig with lower values
model_name
feeling_heard_nat
AIC
1082.951
n_obs
374
lrt_pval
0.055
lrt_chisq
9.247
intercept_12
-3.58
intercept_23
-3.258
intercept_34
-2.901
intercept_45
-1.953
intercept_56
-0.961
intercept_67
0.408
n_factors
4
est_nationality_continentAsia
-0.729
lowerCI_nationality_continentAsia
-1.393
higherCI_nationality_continentAsia
-0.065
se_nationality_continentAsia
0.338
tval_nationality_continentAsia
-2.159
pval_nationality_continentAsia
0.032
est_nationality_continentNorth America
0.435
lowerCI_nationality_continentNorth America
-0.267
higherCI_nationality_continentNorth America
1.136
se_nationality_continentNorth America
0.357
tval_nationality_continentNorth America
1.218
pval_nationality_continentNorth America
0.224
est_nationality_continentOceania
-0.93
lowerCI_nationality_continentOceania
-2.234
higherCI_nationality_continentOceania
0.374
se_nationality_continentOceania
0.663
tval_nationality_continentOceania
-1.402
pval_nationality_continentOceania
0.162
est_nationality_continentSouth America
0.602
lowerCI_nationality_continentSouth America
-0.905
higherCI_nationality_continentSouth America
2.109
se_nationality_continentSouth America
0.766
tval_nationality_continentSouth America
0.785
pval_nationality_continentSouth America
0.433
# affiliationsurvey$affiliation_continent <-factor(survey$affiliation_continent, levels =c("Europe", "Asia", "Africa", "North America", "Oceania", "South America"))m_heard_aff_null <-polr(feeling_heard_rating ~1, data=subset(survey, !is.na(affiliation_continent)))m_heard_aff <-polr(feeling_heard_rating ~ affiliation_continent,data=subset(survey, !is.na(affiliation_continent))) m_heard_aff_out <-collect_out(model = m_heard_aff, null = m_heard_aff_null, name ="feeling_heard_aff", n_factors =5, type ="likert", save ="yes", dir ="../results/survey") m_heard_aff_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
feeling_heard_aff
AIC
1094.802
n_obs
377
lrt_pval
0.122
lrt_chisq
8.695
intercept_12
-3.528
intercept_23
-3.206
intercept_34
-2.85
intercept_45
-1.886
intercept_56
-0.913
intercept_67
0.449
n_factors
5
est_affiliation_continentAsia
-0.667
lowerCI_affiliation_continentAsia
-1.686
higherCI_affiliation_continentAsia
0.351
se_affiliation_continentAsia
0.518
tval_affiliation_continentAsia
-1.288
pval_affiliation_continentAsia
0.199
est_affiliation_continentAfrica
15.592
lowerCI_affiliation_continentAfrica
15.592
higherCI_affiliation_continentAfrica
15.592
se_affiliation_continentAfrica
0
tval_affiliation_continentAfrica
6117895554
pval_affiliation_continentAfrica
0
est_affiliation_continentNorth America
0.438
lowerCI_affiliation_continentNorth America
-0.454
higherCI_affiliation_continentNorth America
1.329
se_affiliation_continentNorth America
0.453
tval_affiliation_continentNorth America
0.965
pval_affiliation_continentNorth America
0.335
est_affiliation_continentOceania
-0.369
lowerCI_affiliation_continentOceania
-1.606
higherCI_affiliation_continentOceania
0.867
se_affiliation_continentOceania
0.629
tval_affiliation_continentOceania
-0.587
pval_affiliation_continentOceania
0.557
est_affiliation_continentSouth America
15.592
lowerCI_affiliation_continentSouth America
15.592
higherCI_affiliation_continentSouth America
15.592
se_affiliation_continentSouth America
0
tval_affiliation_continentSouth America
3058988690
pval_affiliation_continentSouth America
0
# expatsurvey$expat <-factor(survey$expat, levels =c("No expat", "Expat"))m_heard_expat_null <-polr(feeling_heard_rating ~1, data=subset(survey, !is.na(expat)))m_heard_expat <-polr(feeling_heard_rating ~ expat,data=subset(survey, !is.na(expat))) m_heard_expat_out <-collect_out(model = m_heard_expat, null = m_heard_expat_null, name ="feeling_heard_expat", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_heard_expat_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
feeling_heard_expat
AIC
1077.053
n_obs
371
lrt_pval
0.197
lrt_chisq
1.661
intercept_12
-3.381
intercept_23
-3.06
intercept_34
-2.706
intercept_45
-1.775
intercept_56
-0.806
intercept_67
0.561
n_factors
1
est_expatExpat
0.245
lowerCI_expatExpat
-0.129
higherCI_expatExpat
0.619
se_expatExpat
0.19
tval_expatExpat
1.287
pval_expatExpat
0.199
# english level survey$english_comfort_rating <-as.numeric(as.character(survey$english_comfort_rating))m_heard_english_null <-polr(feeling_heard_rating ~1, data=subset(survey, !is.na(english_comfort_rating)))m_heard_english <-polr(feeling_heard_rating ~ english_comfort_rating,data=subset(survey, !is.na(english_comfort_rating))) m_heard_english_out <-collect_out(model = m_heard_english, null = m_heard_english_null, name ="feeling_heard_english", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_heard_english_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
feeling_heard_english
AIC
1098.731
n_obs
384
lrt_pval
0
lrt_chisq
14.376
intercept_12
-1.169
intercept_23
-0.845
intercept_34
-0.48
intercept_45
0.5
intercept_56
1.517
intercept_67
2.903
n_factors
1
est_english_comfort_rating
0.381
lowerCI_english_comfort_rating
0.186
higherCI_english_comfort_rating
0.575
se_english_comfort_rating
0.099
tval_english_comfort_rating
3.841
pval_english_comfort_rating
0
# expert ratingsurvey$expertise_rating <-as.numeric(as.character(survey$expertise_rating))m_heard_expert_null <-polr(feeling_heard_rating ~1, data=subset(survey, !is.na(expertise_rating)))m_heard_expert <-polr(feeling_heard_rating ~ expertise_rating,data=subset(survey, !is.na(expertise_rating))) m_heard_expert_out <-collect_out(model = m_heard_expert, null = m_heard_expert_null, name ="feeling_heard_expert", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_heard_expert_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
feeling_heard_expert
AIC
1091.194
n_obs
384
lrt_pval
0
lrt_chisq
21.914
intercept_12
-2.285
intercept_23
-1.962
intercept_34
-1.605
intercept_45
-0.636
intercept_56
0.383
intercept_67
1.788
n_factors
1
est_expertise_rating
0.274
lowerCI_expertise_rating
0.158
higherCI_expertise_rating
0.391
se_expertise_rating
0.059
tval_expertise_rating
4.622
pval_expertise_rating
0
### build final model only with significant variablesm_heard_null <-polr(feeling_heard_rating ~1, data=subset(survey, !is.na(expertise_rating) &!is.na(english_comfort_rating)))m_heard <-polr(feeling_heard_rating ~english_comfort_rating + expertise_rating, data=subset(survey, !is.na(expertise_rating) &!is.na(english_comfort_rating)))drop1(m_heard, test ="Chisq")
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
english_comfort_rating 0.283610 0.102551 2.7656 0.0059628 **
expertise_rating 0.235642 0.061224 3.8488 0.0001394 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
m_heard_out <-collect_out(model = m_heard, null = m_heard_null, name ="feeling_heard_final", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_heard_out %>%t() %>%kbl() %>%kable_classic_2()
model_name
feeling_heard_final
AIC
1085.704
n_obs
384
lrt_pval
0
lrt_chisq
29.404
intercept_12
-0.706
intercept_23
-0.38
intercept_34
-0.015
intercept_45
0.972
intercept_56
2.009
intercept_67
3.436
n_factors
2
est_english_comfort_rating
0.284
lowerCI_english_comfort_rating
0.082
higherCI_english_comfort_rating
0.485
se_english_comfort_rating
0.103
tval_english_comfort_rating
2.766
pval_english_comfort_rating
0.006
est_expertise_rating
0.236
lowerCI_expertise_rating
0.115
higherCI_expertise_rating
0.356
se_expertise_rating
0.061
tval_expertise_rating
3.849
pval_expertise_rating
0
The results indicate that none of the social identity variables (gender, lgbtq, nationality, affiliation (but this model did not converge)) affected whether a person felt heard during the congress. However, people who are more comfortable speaking English felt heard more, and people that rated their expertise in the field higher also felt heard more.
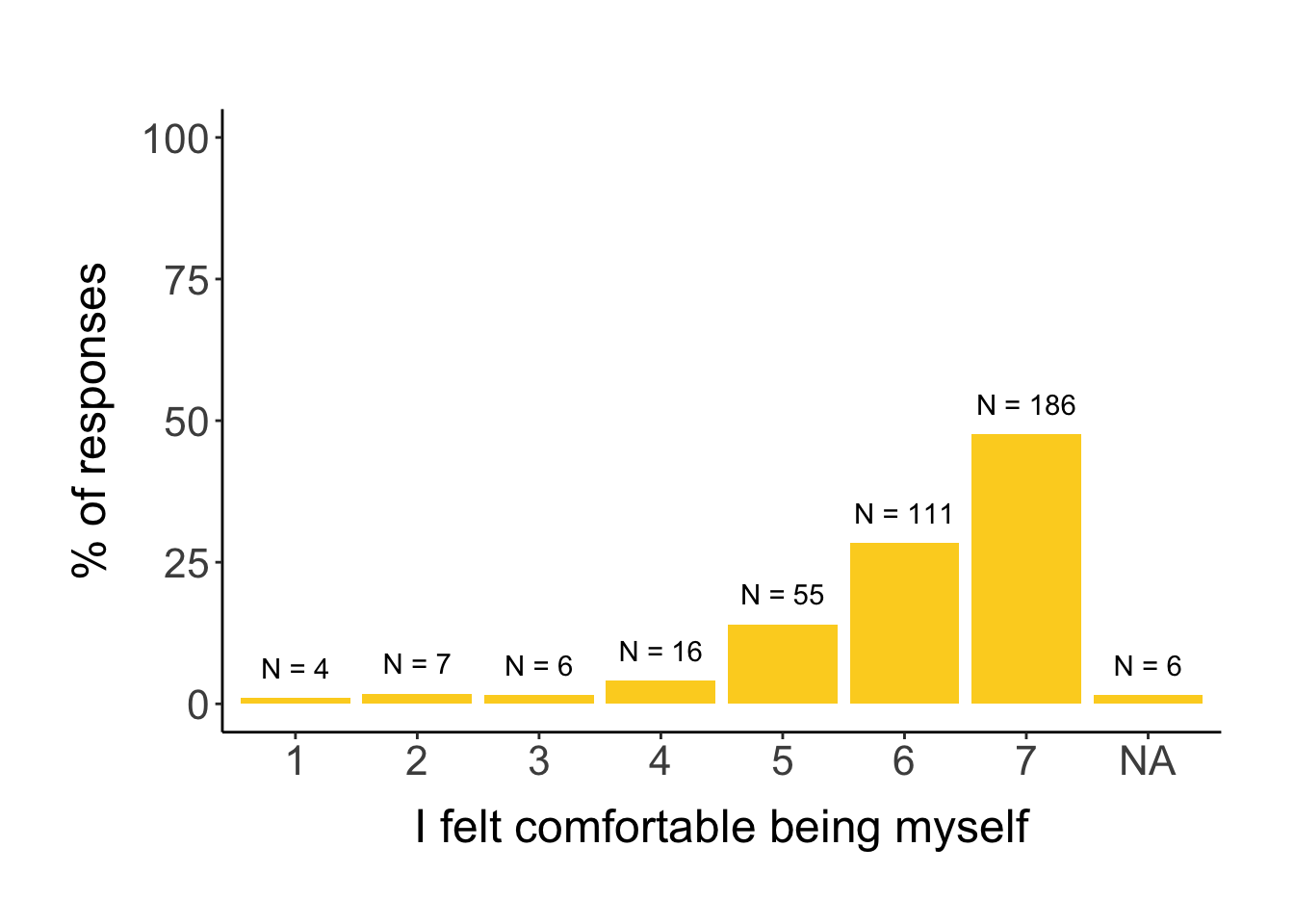
7.2.2 Feeling comfortable being yourself
# first, we explore the distribution of answersggplot(survey, aes(comfort_being_yourself_rating)) +geom_histogram(stat="count", aes(y=stat(count/sum(count)*100)), fill = clrs[11]) +geom_text(aes(label =paste0("N = ", ..count..), y =stat(count/sum(count)*100)), stat="count", vjust=-1) +ylim(0, 100) +labs(x ="I felt comfortable being myself", y ="% of responses")
# then we test the effect of each of the social identity variables# genderm_yourself_gender_null <-polr(comfort_being_yourself_rating ~1, data=subset(survey, !is.na(gender)))m_yourself_gender <-polr(comfort_being_yourself_rating ~ gender,data=survey) m_yourself_gender_out <-collect_out(model = m_yourself_gender, null = m_yourself_gender_null, name ="comf_yourself_gender", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_yourself_gender_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
comf_yourself_gender
AIC
982.799
n_obs
374
lrt_pval
0.001
lrt_chisq
13.295
intercept_12
-4.984
intercept_23
-3.945
intercept_34
-3.486
intercept_45
-2.765
intercept_56
-1.599
intercept_67
-0.289
n_factors
2
est_genderFemale
-0.464
lowerCI_genderFemale
-0.894
higherCI_genderFemale
-0.034
se_genderFemale
0.219
tval_genderFemale
-2.123
pval_genderFemale
0.034
est_genderNon-binary
-2.323
lowerCI_genderNon-binary
-3.628
higherCI_genderNon-binary
-1.018
se_genderNon-binary
0.664
tval_genderNon-binary
-3.5
pval_genderNon-binary
0.001
# lgbtqia m_yourself_lgbtq_null <-polr(comfort_being_yourself_rating ~1, data=subset(survey, !is.na(lgbtq)))m_yourself_lgbtq <-polr(comfort_being_yourself_rating ~ lgbtq,data=subset(survey, !is.na(lgbtq))) m_yourself_lgbtq_out <-collect_out(model = m_yourself_lgbtq, null = m_yourself_lgbtq_null, name ="comf_yourself_lgbtq", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_yourself_lgbtq_out %>%t() %>%kbl() %>%kable_classic_2() # almost significant
model_name
comf_yourself_lgbtq
AIC
949.434
n_obs
361
lrt_pval
0.069
lrt_chisq
3.3
intercept_12
-4.88
intercept_23
-3.655
intercept_34
-3.166
intercept_45
-2.422
intercept_56
-1.342
intercept_67
-0.027
n_factors
1
est_lgbtqYes
-0.478
lowerCI_lgbtqYes
-0.993
higherCI_lgbtqYes
0.037
se_lgbtqYes
0.262
tval_lgbtqYes
-1.826
pval_lgbtqYes
0.069
# nationalitym_yourself_nat_null <-polr(comfort_being_yourself_rating ~1, data=subset(survey, !is.na(nationality_continent)))m_yourself_nat <-polr(comfort_being_yourself_rating ~ nationality_continent,data=survey) m_yourself_nat_out <-collect_out(model = m_yourself_nat, null = m_yourself_nat_null, name ="comf_yourself_nat", n_factors =4, type ="likert", save ="yes", dir ="../results/survey") m_yourself_nat_out %>%t() %>%kbl() %>%kable_classic_2() # not significant, but East Europe is sig with higher values
model_name
comf_yourself_nat
AIC
1001.98
n_obs
375
lrt_pval
0.735
lrt_chisq
2.006
intercept_12
-4.524
intercept_23
-3.494
intercept_34
-3.044
intercept_45
-2.337
intercept_56
-1.193
intercept_67
0.081
n_factors
4
est_nationality_continentAsia
0.071
lowerCI_nationality_continentAsia
-0.574
higherCI_nationality_continentAsia
0.715
se_nationality_continentAsia
0.328
tval_nationality_continentAsia
0.215
pval_nationality_continentAsia
0.83
est_nationality_continentNorth America
-0.209
lowerCI_nationality_continentNorth America
-0.88
higherCI_nationality_continentNorth America
0.463
se_nationality_continentNorth America
0.342
tval_nationality_continentNorth America
-0.611
pval_nationality_continentNorth America
0.541
est_nationality_continentOceania
0.352
lowerCI_nationality_continentOceania
-1.124
higherCI_nationality_continentOceania
1.828
se_nationality_continentOceania
0.751
tval_nationality_continentOceania
0.469
pval_nationality_continentOceania
0.639
est_nationality_continentSouth America
0.91
lowerCI_nationality_continentSouth America
-0.748
higherCI_nationality_continentSouth America
2.567
se_nationality_continentSouth America
0.843
tval_nationality_continentSouth America
1.079
pval_nationality_continentSouth America
0.281
# affiliationm_yourself_aff_null <-polr(comfort_being_yourself_rating ~1, data=subset(survey, !is.na(affiliation_continent)))m_yourself_aff <-polr(comfort_being_yourself_rating ~ affiliation_continent,data=subset(survey, !is.na(affiliation_continent))) m_yourself_aff_out <-collect_out(model = m_yourself_aff, null = m_yourself_aff_null, name ="comf_yourself_aff", n_factors =5, type ="likert", save ="yes", dir ="../results/survey") m_yourself_aff_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
comf_yourself_aff
AIC
999.597
n_obs
378
lrt_pval
0.29
lrt_chisq
6.171
intercept_12
-4.515
intercept_23
-3.583
intercept_34
-3.095
intercept_45
-2.355
intercept_56
-1.194
intercept_67
0.102
n_factors
5
est_affiliation_continentAsia
0.588
lowerCI_affiliation_continentAsia
-0.43
higherCI_affiliation_continentAsia
1.607
se_affiliation_continentAsia
0.518
tval_affiliation_continentAsia
1.136
pval_affiliation_continentAsia
0.257
est_affiliation_continentAfrica
15.292
lowerCI_affiliation_continentAfrica
15.292
higherCI_affiliation_continentAfrica
15.292
se_affiliation_continentAfrica
0
tval_affiliation_continentAfrica
5516237801
pval_affiliation_continentAfrica
0
est_affiliation_continentNorth America
0.131
lowerCI_affiliation_continentNorth America
-0.753
higherCI_affiliation_continentNorth America
1.015
se_affiliation_continentNorth America
0.45
tval_affiliation_continentNorth America
0.291
pval_affiliation_continentNorth America
0.771
est_affiliation_continentOceania
-0.349
lowerCI_affiliation_continentOceania
-1.555
higherCI_affiliation_continentOceania
0.858
se_affiliation_continentOceania
0.614
tval_affiliation_continentOceania
-0.569
pval_affiliation_continentOceania
0.57
est_affiliation_continentSouth America
15.292
lowerCI_affiliation_continentSouth America
15.292
higherCI_affiliation_continentSouth America
15.292
se_affiliation_continentSouth America
0
tval_affiliation_continentSouth America
2758136541
pval_affiliation_continentSouth America
0
# expatm_yourself_expat_null <-polr(comfort_being_yourself_rating ~1, data=subset(survey, !is.na(expat)))m_yourself_expat <-polr(comfort_being_yourself_rating ~ expat,data=subset(survey, !is.na(expat))) m_yourself_expat_out <-collect_out(model = m_yourself_expat, null = m_yourself_expat_null, name ="comf_yourself_expat", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_yourself_expat_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
comf_yourself_expat
AIC
986.957
n_obs
372
lrt_pval
0.945
lrt_chisq
0.005
intercept_12
-4.53
intercept_23
-3.595
intercept_34
-3.109
intercept_45
-2.37
intercept_56
-1.208
intercept_67
0.069
n_factors
1
est_expatExpat
-0.013
lowerCI_expatExpat
-0.394
higherCI_expatExpat
0.368
se_expatExpat
0.194
tval_expatExpat
-0.069
pval_expatExpat
0.945
# english level survey$english_comfort_rating <-as.numeric(as.character(survey$english_comfort_rating))m_yourself_english_null <-polr(comfort_being_yourself_rating ~1, data=subset(survey, !is.na(english_comfort_rating)))m_yourself_english <-polr(comfort_being_yourself_rating ~ english_comfort_rating,data=subset(survey, !is.na(english_comfort_rating))) m_yourself_english_out <-collect_out(model = m_yourself_english, null = m_yourself_english_null, name ="comf_yourself_english", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_yourself_english_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
comf_yourself_english
AIC
1008.542
n_obs
385
lrt_pval
0.001
lrt_chisq
10.598
intercept_12
-2.451
intercept_23
-1.413
intercept_34
-0.95
intercept_45
-0.227
intercept_56
0.944
intercept_67
2.253
n_factors
1
est_english_comfort_rating
0.339
lowerCI_english_comfort_rating
0.135
higherCI_english_comfort_rating
0.542
se_english_comfort_rating
0.104
tval_english_comfort_rating
3.269
pval_english_comfort_rating
0.001
# expert ratingsurvey$expertise_rating <-as.numeric(as.character(survey$expertise_rating))m_yourself_expert_null <-polr(comfort_being_yourself_rating ~1, data=subset(survey, !is.na(expertise_rating)))m_yourself_expert <-polr(comfort_being_yourself_rating ~ expertise_rating,data=subset(survey, !is.na(expertise_rating))) m_yourself_expert_out <-collect_out(model = m_yourself_expert, null = m_yourself_expert_null, name ="comf_yourself_expert", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_yourself_expert_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
comf_yourself_expert
AIC
1001.373
n_obs
385
lrt_pval
0
lrt_chisq
17.767
intercept_12
-3.436
intercept_23
-2.399
intercept_34
-1.942
intercept_45
-1.228
intercept_56
-0.061
intercept_67
1.268
n_factors
1
est_expertise_rating
0.248
lowerCI_expertise_rating
0.131
higherCI_expertise_rating
0.365
se_expertise_rating
0.059
tval_expertise_rating
4.169
pval_expertise_rating
0
### build final model only with significant variablesm_yourself_null <-polr(comfort_being_yourself_rating ~1, data=subset(survey, !is.na(gender) &!is.na(expertise_rating) &!is.na(english_comfort_rating)))m_yourself <-polr(comfort_being_yourself_rating ~ gender + english_comfort_rating + expertise_rating, data=subset(survey, !is.na(gender) &!is.na(expertise_rating) &!is.na(english_comfort_rating)))drop1(m_yourself, test ="Chisq")
m_yourself_out <-collect_out(model = m_yourself, null = m_yourself_null, name ="comf_yourself_final", n_factors =4, type ="likert", save ="yes", dir ="../results/survey") m_yourself_out %>%kbl() %>%kable_classic_2()
model_name
AIC
n_obs
lrt_pval
lrt_chisq
intercept_12
intercept_23
intercept_34
intercept_45
intercept_56
intercept_67
n_factors
est_genderFemale
lowerCI_genderFemale
higherCI_genderFemale
se_genderFemale
tval_genderFemale
pval_genderFemale
est_genderNon-binary
lowerCI_genderNon-binary
higherCI_genderNon-binary
se_genderNon-binary
tval_genderNon-binary
pval_genderNon-binary
est_english_comfort_rating
lowerCI_english_comfort_rating
higherCI_english_comfort_rating
se_english_comfort_rating
tval_english_comfort_rating
pval_english_comfort_rating
est_expertise_rating
lowerCI_expertise_rating
higherCI_expertise_rating
se_expertise_rating
tval_expertise_rating
pval_expertise_rating
comf_yourself_final
962.684
374
0
37.41
-2.277
-1.218
-0.74
0.002
1.2
2.572
4
-0.475
-0.911
-0.039
0.222
-2.141
0.033
-2.261
-3.588
-0.934
0.675
-3.351
0.001
0.281
0.067
0.496
0.109
2.579
0.01
0.218
0.097
0.339
0.062
3.534
0
The results indicate that lgbtq and nationality did not affect whether a person felt comfortable being themselves during the congress (but lgbtq came close to significance). However, men feel more comfortable than women and non-binary people feel less comfortable being themselves compared to women. People who are more comfortable speaking English felt more comfortable being themselves, and people that rated their expertise in the field higher also felt more comfortable being themselves.
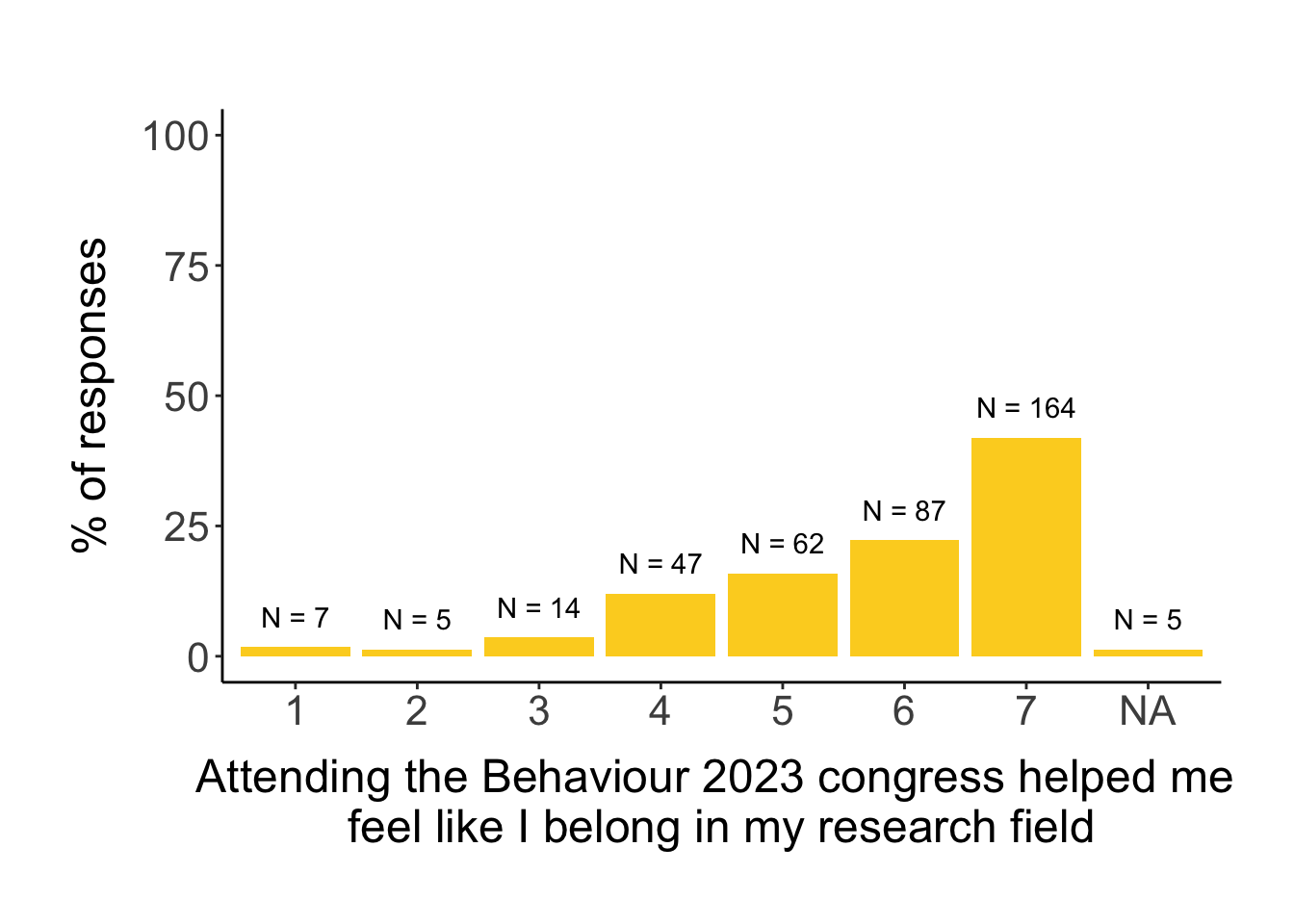
7.2.3 Sense of belonging
# first, we explore the distribution of answersggplot(survey, aes(sense_of_belonging_rating)) +geom_histogram(stat="count", aes(y=stat(count/sum(count)*100)), fill = clrs[11]) +geom_text(aes(label =paste0("N = ", ..count..), y =stat(count/sum(count)*100)), stat="count", vjust=-1) +ylim(0, 100) +labs(x ="Attending the Behaviour 2023 congress helped me feel like I belong in my research field", y ="% of responses")
# then we test the effect of each of the social identity variables# genderm_sob_gender_null <-polr(sense_of_belonging_rating ~1, data=subset(survey, !is.na(gender)))m_sob_gender <-polr(sense_of_belonging_rating ~ gender,data=survey) m_sob_gender_out <-collect_out(model = m_sob_gender, null = m_sob_gender_null, name ="belonging_gender", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_sob_gender_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
belonging_gender
AIC
1137.815
n_obs
375
lrt_pval
0.107
lrt_chisq
4.475
intercept_12
-4.216
intercept_23
-3.662
intercept_34
-2.89
intercept_45
-1.684
intercept_56
-0.84
intercept_67
0.072
n_factors
2
est_genderFemale
-0.316
lowerCI_genderFemale
-0.724
higherCI_genderFemale
0.092
se_genderFemale
0.207
tval_genderFemale
-1.525
pval_genderFemale
0.128
est_genderNon-binary
-1.181
lowerCI_genderNon-binary
-2.505
higherCI_genderNon-binary
0.144
se_genderNon-binary
0.674
tval_genderNon-binary
-1.753
pval_genderNon-binary
0.081
# lgbtqia m_sob_lgbtq_null <-polr(sense_of_belonging_rating ~1, data=subset(survey, !is.na(lgbtq)))m_sob_lgbtq <-polr(sense_of_belonging_rating ~ lgbtq,data=subset(survey, !is.na(lgbtq))) m_sob_lgbtq_out <-collect_out(model = m_sob_lgbtq, null = m_sob_lgbtq_null, name ="belonging_lgbtq", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_sob_lgbtq_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
belonging_lgbtq
AIC
1100.466
n_obs
362
lrt_pval
0.365
lrt_chisq
0.82
intercept_12
-3.969
intercept_23
-3.505
intercept_34
-2.687
intercept_45
-1.469
intercept_56
-0.618
intercept_67
0.274
n_factors
1
est_lgbtqYes
-0.23
lowerCI_lgbtqYes
-0.729
higherCI_lgbtqYes
0.269
se_lgbtqYes
0.254
tval_lgbtqYes
-0.908
pval_lgbtqYes
0.365
# nationalitym_sob_nat_null <-polr(sense_of_belonging_rating ~1, data=subset(survey, !is.na(nationality_continent)))m_sob_nat <-polr(sense_of_belonging_rating ~ nationality_continent,data=survey) m_sob_nat_out <-collect_out(model = m_sob_nat, null = m_sob_nat_null, name ="belonging_nat", n_factors =4, type ="likert", save ="yes", dir ="../results/survey") m_sob_nat_out %>%t() %>%kbl() %>%kable_classic_2() # not significant, but North America is borderline sig with higher values
model_name
belonging_nat
AIC
1137.541
n_obs
376
lrt_pval
0.112
lrt_chisq
7.504
intercept_12
-3.895
intercept_23
-3.343
intercept_34
-2.532
intercept_45
-1.366
intercept_56
-0.567
intercept_67
0.377
n_factors
4
est_nationality_continentAsia
0.314
lowerCI_nationality_continentAsia
-0.357
higherCI_nationality_continentAsia
0.985
se_nationality_continentAsia
0.341
tval_nationality_continentAsia
0.919
pval_nationality_continentAsia
0.358
est_nationality_continentNorth America
0.647
lowerCI_nationality_continentNorth America
-0.012
higherCI_nationality_continentNorth America
1.306
se_nationality_continentNorth America
0.335
tval_nationality_continentNorth America
1.93
pval_nationality_continentNorth America
0.054
est_nationality_continentOceania
-0.645
lowerCI_nationality_continentOceania
-1.905
higherCI_nationality_continentOceania
0.616
se_nationality_continentOceania
0.641
tval_nationality_continentOceania
-1.006
pval_nationality_continentOceania
0.315
est_nationality_continentSouth America
1.159
lowerCI_nationality_continentSouth America
-0.517
higherCI_nationality_continentSouth America
2.834
se_nationality_continentSouth America
0.852
tval_nationality_continentSouth America
1.36
pval_nationality_continentSouth America
0.175
# affiliationm_sob_aff_null <-polr(sense_of_belonging_rating ~1, data=subset(survey, !is.na(affiliation_continent)))m_sob_aff <-polr(sense_of_belonging_rating ~ affiliation_continent,data=subset(survey, !is.na(affiliation_continent))) m_sob_aff_out <-collect_out(model = m_sob_aff, null = m_sob_aff_null, name ="belonging_aff", n_factors =5, type ="likert", save ="yes", dir ="../results/survey") m_sob_aff_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
belonging_aff
AIC
1141.766
n_obs
379
lrt_pval
0.013
lrt_chisq
14.457
intercept_12
-3.899
intercept_23
-3.346
intercept_34
-2.533
intercept_45
-1.381
intercept_56
-0.551
intercept_67
0.415
n_factors
5
est_affiliation_continentAsia
0.734
lowerCI_affiliation_continentAsia
-0.227
higherCI_affiliation_continentAsia
1.694
se_affiliation_continentAsia
0.488
tval_affiliation_continentAsia
1.502
pval_affiliation_continentAsia
0.134
est_affiliation_continentAfrica
-0.063
lowerCI_affiliation_continentAfrica
-2.932
higherCI_affiliation_continentAfrica
2.806
se_affiliation_continentAfrica
1.459
tval_affiliation_continentAfrica
-0.043
pval_affiliation_continentAfrica
0.966
est_affiliation_continentNorth America
1.439
lowerCI_affiliation_continentNorth America
0.409
higherCI_affiliation_continentNorth America
2.469
se_affiliation_continentNorth America
0.524
tval_affiliation_continentNorth America
2.747
pval_affiliation_continentNorth America
0.006
est_affiliation_continentOceania
0.214
lowerCI_affiliation_continentOceania
-0.827
higherCI_affiliation_continentOceania
1.255
se_affiliation_continentOceania
0.529
tval_affiliation_continentOceania
0.405
pval_affiliation_continentOceania
0.686
est_affiliation_continentSouth America
16.065
lowerCI_affiliation_continentSouth America
16.065
higherCI_affiliation_continentSouth America
16.065
se_affiliation_continentSouth America
0
tval_affiliation_continentSouth America
2685232830
pval_affiliation_continentSouth America
0
# expatm_sob_expat_null <-polr(sense_of_belonging_rating ~1, data=subset(survey, !is.na(expat)))m_sob_expat <-polr(sense_of_belonging_rating ~ expat,data=subset(survey, !is.na(expat))) m_sob_expat_out <-collect_out(model = m_sob_expat, null = m_sob_expat_null, name ="belonging_expat", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_sob_expat_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
belonging_expat
AIC
1130.934
n_obs
373
lrt_pval
0.471
lrt_chisq
0.519
intercept_12
-4.023
intercept_23
-3.47
intercept_34
-2.657
intercept_45
-1.514
intercept_56
-0.714
intercept_67
0.223
n_factors
1
est_expatExpat
-0.136
lowerCI_expatExpat
-0.508
higherCI_expatExpat
0.236
se_expatExpat
0.189
tval_expatExpat
-0.72
pval_expatExpat
0.472
# english level survey$english_comfort_rating <-as.numeric(as.character(survey$english_comfort_rating))m_sob_english_null <-polr(sense_of_belonging_rating ~1, data=subset(survey, !is.na(english_comfort_rating)))m_sob_english <-polr(sense_of_belonging_rating ~ english_comfort_rating,data=subset(survey, !is.na(english_comfort_rating))) m_sob_english_out <-collect_out(model = m_sob_english, null = m_sob_english_null, name ="belonging_english", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_sob_english_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
belonging_english
AIC
1151.747
n_obs
386
lrt_pval
0
lrt_chisq
19.426
intercept_12
-1.316
intercept_23
-0.759
intercept_34
0.063
intercept_45
1.27
intercept_56
2.144
intercept_67
3.105
n_factors
1
est_english_comfort_rating
0.433
lowerCI_english_comfort_rating
0.241
higherCI_english_comfort_rating
0.626
se_english_comfort_rating
0.098
tval_english_comfort_rating
4.421
pval_english_comfort_rating
0
# expert ratingsurvey$expertise_rating <-as.numeric(as.character(survey$expertise_rating))m_sob_expert_null <-polr(sense_of_belonging_rating ~1, data=subset(survey, !is.na(expertise_rating)))m_sob_expert <-polr(sense_of_belonging_rating ~ expertise_rating,data=subset(survey, !is.na(expertise_rating))) m_sob_expert_out <-collect_out(model = m_sob_expert, null = m_sob_expert_null, name ="belonging_expert", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_sob_expert_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
belonging_expert
AIC
1124.873
n_obs
386
lrt_pval
0
lrt_chisq
46.3
intercept_12
-2.269
intercept_23
-1.71
intercept_34
-0.886
intercept_45
0.339
intercept_56
1.257
intercept_67
2.281
n_factors
1
est_expertise_rating
0.4
lowerCI_expertise_rating
0.282
higherCI_expertise_rating
0.518
se_expertise_rating
0.06
tval_expertise_rating
6.661
pval_expertise_rating
0
### build final model only with significant variablesm_sob_null <-polr(sense_of_belonging_rating ~1, data=subset(survey, !is.na(expertise_rating) &!is.na(english_comfort_rating) &!is.na(affiliation_continent)))m_sob <-polr(sense_of_belonging_rating ~ affiliation_continent + english_comfort_rating + expertise_rating, data=subset(survey, !is.na(expertise_rating) &!is.na(english_comfort_rating)&!is.na(affiliation_continent)))drop1(m_sob, test ="Chisq")
t test of coefficients:
Estimate Std. Error t value
affiliation_continentAsia 8.8114e-01 5.1664e-01 1.7055e+00
affiliation_continentAfrica -1.0164e+00 1.4763e+00 -6.8850e-01
affiliation_continentNorth America 1.1562e+00 5.2882e-01 2.1864e+00
affiliation_continentOceania 6.4092e-02 5.2423e-01 1.2230e-01
affiliation_continentSouth America 1.5758e+01 2.7271e-08 5.7783e+08
english_comfort_rating 3.1388e-01 1.0360e-01 3.0298e+00
expertise_rating 3.5048e-01 6.3142e-02 5.5507e+00
Pr(>|t|)
affiliation_continentAsia 0.088949 .
affiliation_continentAfrica 0.491597
affiliation_continentNorth America 0.029421 *
affiliation_continentOceania 0.902761
affiliation_continentSouth America < 2.2e-16 ***
english_comfort_rating 0.002621 **
expertise_rating 5.472e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
m_sob_out <-collect_out(model = m_sob, null = m_sob_null, name ="belonging_final", n_factors =7, type ="likert", save ="yes", dir ="../results/survey") m_sob_out %>%t() %>%kbl() %>%kable_classic_2()
model_name
belonging_final
AIC
1096.961
n_obs
379
lrt_pval
0
lrt_chisq
63.263
intercept_12
-0.446
intercept_23
0.118
intercept_34
0.95
intercept_45
2.172
intercept_56
3.096
intercept_67
4.171
n_factors
7
est_affiliation_continentAsia
0.881
lowerCI_affiliation_continentAsia
-0.135
higherCI_affiliation_continentAsia
1.897
se_affiliation_continentAsia
0.517
tval_affiliation_continentAsia
1.706
pval_affiliation_continentAsia
0.089
est_affiliation_continentAfrica
-1.016
lowerCI_affiliation_continentAfrica
-3.919
higherCI_affiliation_continentAfrica
1.887
se_affiliation_continentAfrica
1.476
tval_affiliation_continentAfrica
-0.688
pval_affiliation_continentAfrica
0.492
est_affiliation_continentNorth America
1.156
lowerCI_affiliation_continentNorth America
0.116
higherCI_affiliation_continentNorth America
2.196
se_affiliation_continentNorth America
0.529
tval_affiliation_continentNorth America
2.186
pval_affiliation_continentNorth America
0.029
est_affiliation_continentOceania
0.064
lowerCI_affiliation_continentOceania
-0.967
higherCI_affiliation_continentOceania
1.095
se_affiliation_continentOceania
0.524
tval_affiliation_continentOceania
0.122
pval_affiliation_continentOceania
0.903
est_affiliation_continentSouth America
15.758
lowerCI_affiliation_continentSouth America
15.758
higherCI_affiliation_continentSouth America
15.758
se_affiliation_continentSouth America
0
tval_affiliation_continentSouth America
577826929
pval_affiliation_continentSouth America
0
est_english_comfort_rating
0.314
lowerCI_english_comfort_rating
0.11
higherCI_english_comfort_rating
0.518
se_english_comfort_rating
0.104
tval_english_comfort_rating
3.03
pval_english_comfort_rating
0.003
est_expertise_rating
0.35
lowerCI_expertise_rating
0.226
higherCI_expertise_rating
0.475
se_expertise_rating
0.063
tval_expertise_rating
5.551
pval_expertise_rating
0
The results are very similar to the “Feeling heard” part: none of the social identity variables (gender, lgbtq, nationality) affected whether a person felt that attending the congress increased their Sense of Belonging. However, people who are more comfortable speaking English felt more like it did, and people that rated their expertise in the field higher also felt like attending the congress increased their feeling like they belong in the field.