How did people with different social identities perceive EDI-related issues?
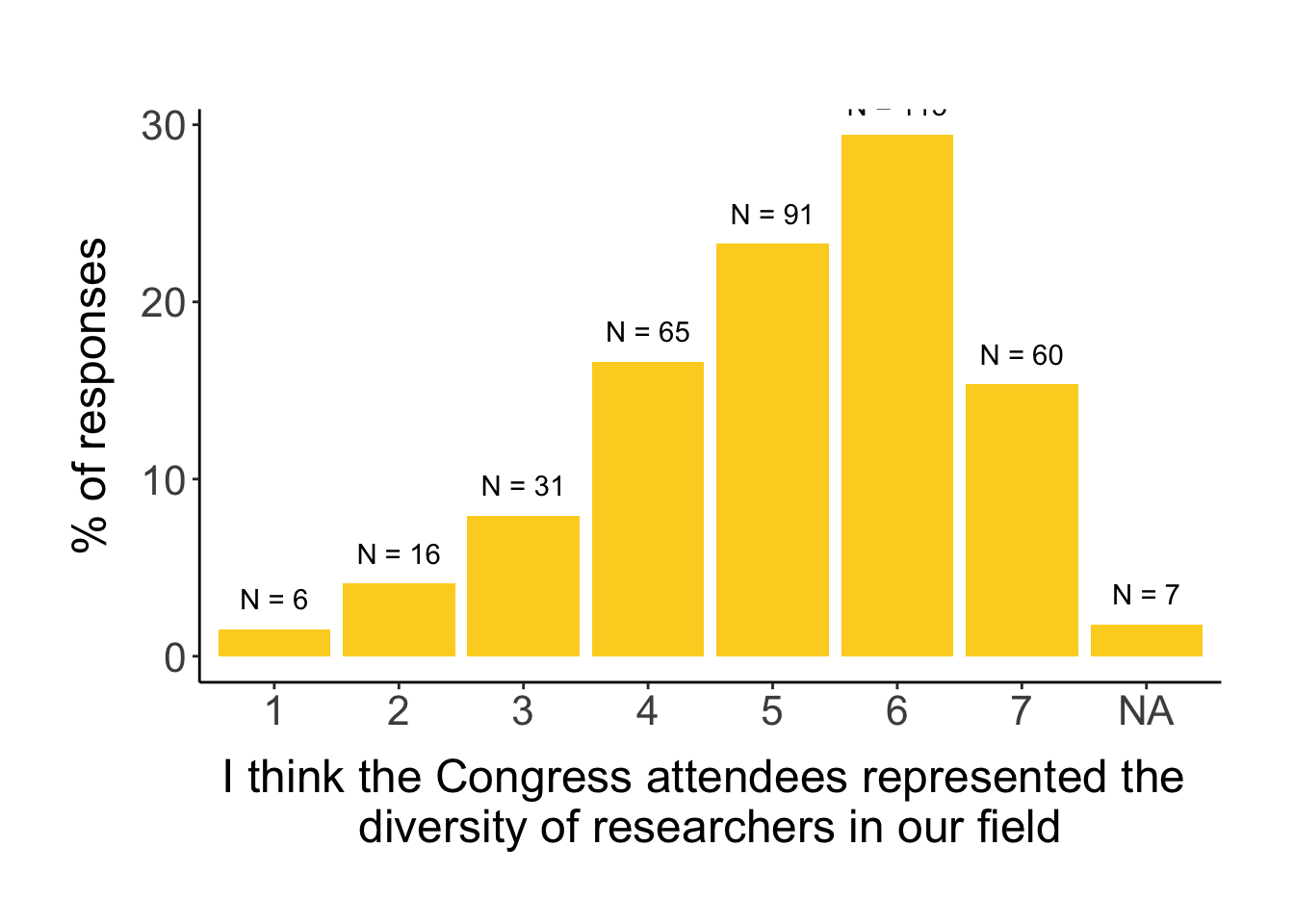
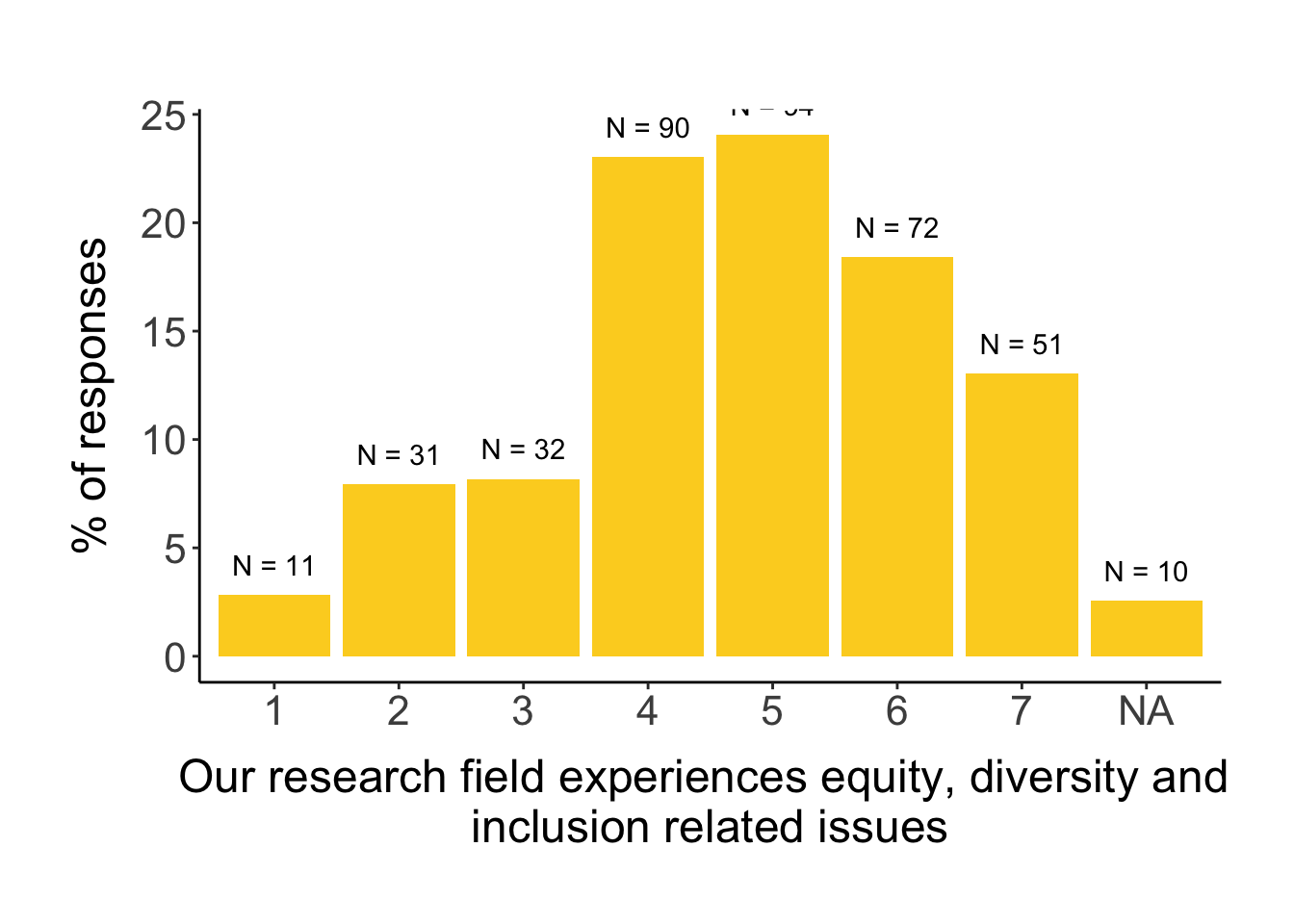
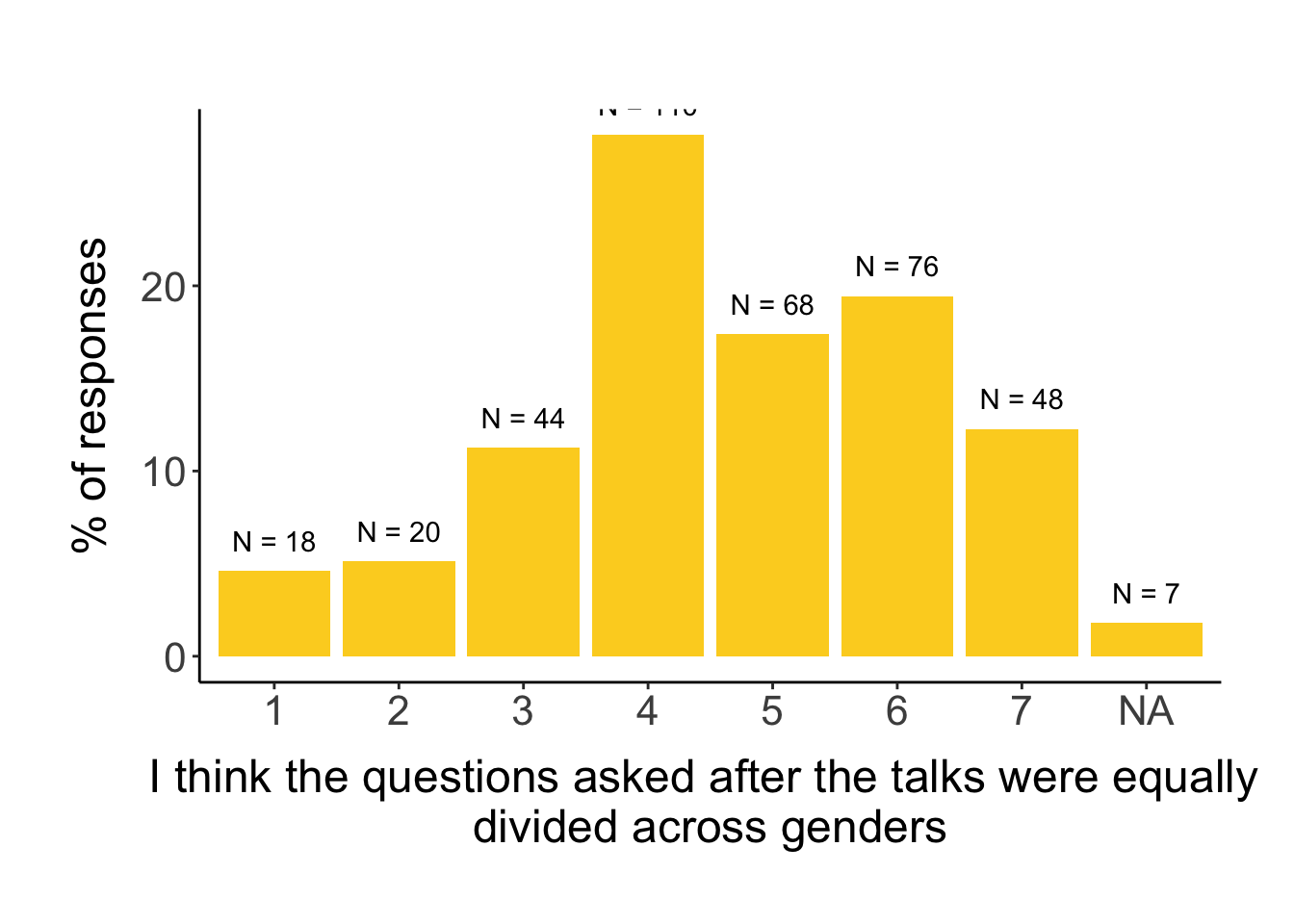
We also asked respondents to answer on a 7-point Likert scale how much they agree with the following three statements on their perception of EDI issues: 1) “I think the Congress attendees represented the diversity of researchers in our field” (“diversity” in short); 2) “Our research field experiences equity, diversity and inclusion related issues (eg. racism, homophobia, harassment, bullying etc.)” (“EDI issues” in short); 3) “I think the questions asked after the talks were equally divided across genders” (“no QA gender disparity” in short).
Similar to the analyses for congress experience, we fitted ordinal GLMs, one per statement, to identify which social identity variables explain variation in the Likert-scale response to the statement. Instead of fitting expertise rating as an independent variable, we fitted career stage (early, mid or late), as more senior researchers are more likely to have experienced different research environments and consequently, potential for EDI issues, which is not always linked to age. We again controlled for the level of comfort a person had speaking English.
8.1 Diversity representation
# first, we explore the distribution of answers# diversityggplot(survey, aes(assess_diversity_congress_rating)) +geom_histogram(stat="count", aes(y=stat(count/sum(count)*100)), fill = clrs[11]) +geom_text(aes(label =paste0("N = ", ..count..), y =stat(count/sum(count)*100)), stat="count", vjust=-1) +labs(x ="I think the Congress attendees represented the diversity of researchers in our field", y ="% of responses")
# then we test the effect of each of the social identity variables# gendersurvey$gender <-factor(survey$gender, levels =c("Male", "Female", "Non-binary"))m_diversity_gender_null <-polr(assess_diversity_congress_rating ~1, data=subset(survey, !is.na(gender)))m_diversity_gender <-polr(assess_diversity_congress_rating ~ gender,data=survey) m_diversity_gender_out <-collect_out(model = m_diversity_gender, null = m_diversity_gender_null, name ="diversity_gender", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_diversity_gender_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
diversity_gender
AIC
1274.876
n_obs
373
lrt_pval
0.011
lrt_chisq
9.049
intercept_12
-4.517
intercept_23
-3.167
intercept_34
-2.192
intercept_45
-1.194
intercept_56
-0.19
intercept_67
1.326
n_factors
2
est_genderFemale
-0.506
lowerCI_genderFemale
-0.905
higherCI_genderFemale
-0.108
se_genderFemale
0.203
tval_genderFemale
-2.498
pval_genderFemale
0.013
est_genderNon-binary
-1.379
lowerCI_genderNon-binary
-2.632
higherCI_genderNon-binary
-0.127
se_genderNon-binary
0.637
tval_genderNon-binary
-2.165
pval_genderNon-binary
0.031
# lgbtqia m_diversity_lgbtq_null <-polr(assess_diversity_congress_rating ~1, data=subset(survey, !is.na(lgbtq)))m_diversity_lgbtq <-polr(assess_diversity_congress_rating ~ lgbtq,data=subset(survey, !is.na(lgbtq))) m_diversity_lgbtq_out <-collect_out(model = m_diversity_lgbtq, null = m_diversity_lgbtq_null, name ="diversity_lgbtq", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_diversity_lgbtq_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
diversity_lgbtq
AIC
1239.239
n_obs
360
lrt_pval
0.008
lrt_chisq
6.947
intercept_12
-4.219
intercept_23
-2.866
intercept_34
-1.881
intercept_45
-0.875
intercept_56
0.115
intercept_67
1.58
n_factors
1
est_lgbtqYes
-0.664
lowerCI_lgbtqYes
-1.161
higherCI_lgbtqYes
-0.167
se_lgbtqYes
0.253
tval_lgbtqYes
-2.629
pval_lgbtqYes
0.009
# nationalitysurvey$nationality_continent <-factor(survey$nationality_continent, levels =c("Europe", "Asia", "North America", "Oceania", "South America"))m_diversity_nat_null <-polr(assess_diversity_congress_rating ~1, data=subset(survey, !is.na(nationality_continent)))m_diversity_nat <-polr(assess_diversity_congress_rating ~ nationality_continent,data=survey) m_diversity_nat_out <-collect_out(model = m_diversity_nat, null = m_diversity_nat_null, name ="diversity_nat", n_factors =4, type ="likert", save ="yes", dir ="../results/survey") m_diversity_nat_out %>%t() %>%kbl() %>%kable_classic_2() # not significant, but Asia is borderline sig with higher values
model_name
diversity_nat
AIC
1281.564
n_obs
374
lrt_pval
0.403
lrt_chisq
4.021
intercept_12
-4.093
intercept_23
-2.8
intercept_34
-1.825
intercept_45
-0.789
intercept_56
0.187
intercept_67
1.718
n_factors
4
est_nationality_continentAsia
0.593
lowerCI_nationality_continentAsia
-0.081
higherCI_nationality_continentAsia
1.267
se_nationality_continentAsia
0.343
tval_nationality_continentAsia
1.73
pval_nationality_continentAsia
0.084
est_nationality_continentNorth America
-0.263
lowerCI_nationality_continentNorth America
-0.907
higherCI_nationality_continentNorth America
0.381
se_nationality_continentNorth America
0.327
tval_nationality_continentNorth America
-0.803
pval_nationality_continentNorth America
0.422
est_nationality_continentOceania
-0.016
lowerCI_nationality_continentOceania
-1.232
higherCI_nationality_continentOceania
1.2
se_nationality_continentOceania
0.618
tval_nationality_continentOceania
-0.026
pval_nationality_continentOceania
0.979
est_nationality_continentSouth America
0.192
lowerCI_nationality_continentSouth America
-1.124
higherCI_nationality_continentSouth America
1.508
se_nationality_continentSouth America
0.669
tval_nationality_continentSouth America
0.287
pval_nationality_continentSouth America
0.774
# affiliationsurvey$affiliation_continent <-factor(survey$affiliation_continent, levels =c("Europe", "Asia", "Africa", "North America", "Oceania", "South America"))m_diversity_aff_null <-polr(assess_diversity_congress_rating ~1, data=subset(survey, !is.na(affiliation_continent)))m_diversity_aff <-polr(assess_diversity_congress_rating ~ affiliation_continent,data=subset(survey, !is.na(affiliation_continent))) m_diversity_aff_out <-collect_out(model = m_diversity_aff, null = m_diversity_aff_null, name ="diversity_aff", n_factors =5, type ="likert", save ="yes", dir ="../results/survey") m_diversity_aff_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
diversity_aff
AIC
1296.609
n_obs
377
lrt_pval
0.555
lrt_chisq
3.96
intercept_12
-4.128
intercept_23
-2.783
intercept_34
-1.81
intercept_45
-0.79
intercept_56
0.192
intercept_67
1.728
n_factors
5
est_affiliation_continentAsia
0.016
lowerCI_affiliation_continentAsia
-0.936
higherCI_affiliation_continentAsia
0.967
se_affiliation_continentAsia
0.484
tval_affiliation_continentAsia
0.033
pval_affiliation_continentAsia
0.974
est_affiliation_continentAfrica
-1.301
lowerCI_affiliation_continentAfrica
-4.183
higherCI_affiliation_continentAfrica
1.581
se_affiliation_continentAfrica
1.465
tval_affiliation_continentAfrica
-0.888
pval_affiliation_continentAfrica
0.375
est_affiliation_continentNorth America
-0.253
lowerCI_affiliation_continentNorth America
-1.179
higherCI_affiliation_continentNorth America
0.673
se_affiliation_continentNorth America
0.471
tval_affiliation_continentNorth America
-0.537
pval_affiliation_continentNorth America
0.591
est_affiliation_continentOceania
0.894
lowerCI_affiliation_continentOceania
-0.156
higherCI_affiliation_continentOceania
1.945
se_affiliation_continentOceania
0.534
tval_affiliation_continentOceania
1.674
pval_affiliation_continentOceania
0.095
est_affiliation_continentSouth America
0.163
lowerCI_affiliation_continentSouth America
-3.45
higherCI_affiliation_continentSouth America
3.775
se_affiliation_continentSouth America
1.837
tval_affiliation_continentSouth America
0.088
pval_affiliation_continentSouth America
0.93
# expatsurvey$expat <-factor(levels=c("No expat", "Expat"), survey$expat)m_diversity_expat_null <-polr(assess_diversity_congress_rating ~1, data=subset(survey, !is.na(expat)))m_diversity_expat <-polr(assess_diversity_congress_rating ~ expat,data=subset(survey, !is.na(expat))) m_diversity_expat_out <-collect_out(model = m_diversity_expat, null = m_diversity_expat_null, name ="diversity_expat", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_diversity_expat_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
diversity_expat
AIC
1268.707
n_obs
371
lrt_pval
0.252
lrt_chisq
1.312
intercept_12
-4.213
intercept_23
-2.918
intercept_34
-1.942
intercept_45
-0.906
intercept_56
0.053
intercept_67
1.587
n_factors
1
est_expatExpat
-0.212
lowerCI_expatExpat
-0.575
higherCI_expatExpat
0.152
se_expatExpat
0.185
tval_expatExpat
-1.145
pval_expatExpat
0.253
# english level survey$english_comfort_rating <-as.numeric(as.character(survey$english_comfort_rating))m_diversity_english_null <-polr(assess_diversity_congress_rating ~1, data=subset(survey, !is.na(english_comfort_rating)))m_diversity_english <-polr(assess_diversity_congress_rating ~ english_comfort_rating,data=subset(survey, !is.na(english_comfort_rating))) m_diversity_english_out <-collect_out(model = m_diversity_english, null = m_diversity_english_null, name ="diversity_english", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_diversity_english_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
diversity_english
AIC
1313.893
n_obs
384
lrt_pval
0.381
lrt_chisq
0.767
intercept_12
-4.679
intercept_23
-3.336
intercept_34
-2.365
intercept_45
-1.343
intercept_56
-0.353
intercept_67
1.155
n_factors
1
est_english_comfort_rating
-0.083
lowerCI_english_comfort_rating
-0.269
higherCI_english_comfort_rating
0.104
se_english_comfort_rating
0.095
tval_english_comfort_rating
-0.873
pval_english_comfort_rating
0.383
# agem_diversity_age_null <-polr(assess_diversity_congress_rating ~1, data=subset(survey, !is.na(age)))m_diversity_age <-polr(assess_diversity_congress_rating ~ age,data=subset(survey, !is.na(age))) m_diversity_age_out <-collect_out(model = m_diversity_age, null = m_diversity_age_null, name ="diversity_age", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_diversity_age_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
diversity_age
AIC
1315.435
n_obs
384
lrt_pval
0.542
lrt_chisq
1.225
intercept_12
-4.133
intercept_23
-2.789
intercept_34
-1.819
intercept_45
-0.799
intercept_56
0.192
intercept_67
1.704
n_factors
2
est_age35-50
-0.048
lowerCI_age35-50
-0.443
higherCI_age35-50
0.348
se_age35-50
0.201
tval_age35-50
-0.237
pval_age35-50
0.813
est_age> 50
0.329
lowerCI_age> 50
-0.314
higherCI_age> 50
0.972
se_age> 50
0.327
tval_age> 50
1.006
pval_age> 50
0.315
### build final model only with significant variablesm_diversity_null <-polr(assess_diversity_congress_rating ~1, data=subset(survey, !is.na(gender) &!is.na(lgbtq)))m_diversity <-polr(assess_diversity_congress_rating ~ gender + lgbtq, data=subset(survey, !is.na(gender) &!is.na(lgbtq)))drop1(m_diversity, test ="Chisq")
t test of coefficients:
Estimate Std. Error t value Pr(>|t|)
genderFemale -0.53345 0.20878 -2.5550 0.01104 *
genderNon-binary -0.83271 0.68289 -1.2194 0.22352
lgbtqYes -0.60211 0.27603 -2.1813 0.02983 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# what about an interaction?m_diversity_interact <-polr(assess_diversity_congress_rating ~ gender*lgbtq, data=subset(survey, !is.na(gender) &!is.na(lgbtq)))drop1(m_diversity_interact, test ="Chisq") #NS
Single term deletions
Model:
assess_diversity_congress_rating ~ gender * lgbtq
Df AIC LRT Pr(>Chi)
<none> 1229.0
gender:lgbtq 1 1227.4 0.41641 0.5187
m_diversity_out <-collect_out(model = m_diversity, null = m_diversity_null, name ="diversity_final", n_factors =3, type ="likert", save ="yes", dir ="../results/survey") m_diversity_out %>%t() %>%kbl() %>%kable_classic_2()
model_name
diversity_final
AIC
1227.38
n_obs
357
lrt_pval
0.002
lrt_chisq
14.497
intercept_12
-4.605
intercept_23
-3.247
intercept_34
-2.259
intercept_45
-1.242
intercept_56
-0.252
intercept_67
1.225
n_factors
3
est_genderFemale
-0.533
lowerCI_genderFemale
-0.944
higherCI_genderFemale
-0.123
se_genderFemale
0.209
tval_genderFemale
-2.555
pval_genderFemale
0.011
est_genderNon-binary
-0.833
lowerCI_genderNon-binary
-2.176
higherCI_genderNon-binary
0.51
se_genderNon-binary
0.683
tval_genderNon-binary
-1.219
pval_genderNon-binary
0.224
est_lgbtqYes
-0.602
lowerCI_lgbtqYes
-1.145
higherCI_lgbtqYes
-0.059
se_lgbtqYes
0.276
tval_lgbtqYes
-2.181
pval_lgbtqYes
0.03
The results indicate that gender and LGBTQ+ identity affected whether a person agreed more with the diversity of researchers in our field was represented at the congress. Men had higher agreement compared to women, and LGBTQ+ people had lower agreement compared to non-LGBTQ+ people.
8.2 EDI issues
# first, we explore the distribution of answers# edi issuesggplot(survey, aes(assess_edi_issues_rating)) +geom_histogram(stat="count", aes(y=stat(count/sum(count)*100)), fill = clrs[11]) +geom_text(aes(label =paste0("N = ", ..count..), y =stat(count/sum(count)*100)), stat="count", vjust=-1) +labs(x ="Our research field experiences equity, diversity and inclusion related issues", y ="% of responses")
# then we test the effect of each of the social identity variables# genderm_edi_issues_gender_null <-polr(assess_edi_issues_rating ~1, data=subset(survey, !is.na(gender)))m_edi_issues_gender <-polr(assess_edi_issues_rating ~ gender,data=survey) m_edi_issues_gender_out <-collect_out(model = m_edi_issues_gender, null = m_edi_issues_gender_null, name ="edi_issues_gender", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_edi_issues_gender_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
edi_issues_gender
AIC
1323.308
n_obs
370
lrt_pval
0.004
lrt_chisq
10.917
intercept_12
-3.185
intercept_23
-1.7
intercept_34
-0.994
intercept_45
0.172
intercept_56
1.232
intercept_67
2.367
n_factors
2
est_genderFemale
0.628
lowerCI_genderFemale
0.225
higherCI_genderFemale
1.032
se_genderFemale
0.205
tval_genderFemale
3.062
pval_genderFemale
0.002
est_genderNon-binary
1.231
lowerCI_genderNon-binary
-0.066
higherCI_genderNon-binary
2.527
se_genderNon-binary
0.659
tval_genderNon-binary
1.867
pval_genderNon-binary
0.063
# lgbtqia m_edi_issues_lgbtq_null <-polr(assess_edi_issues_rating ~1, data=subset(survey, !is.na(lgbtq)))m_edi_issues_lgbtq <-polr(assess_edi_issues_rating ~ lgbtq,data=subset(survey, !is.na(lgbtq))) m_edi_issues_lgbtq_out <-collect_out(model = m_edi_issues_lgbtq, null = m_edi_issues_lgbtq_null, name ="edi_issues_lgbtq", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_edi_issues_lgbtq_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
edi_issues_lgbtq
AIC
1279.769
n_obs
357
lrt_pval
0.001
lrt_chisq
10.4
intercept_12
-3.45
intercept_23
-1.991
intercept_34
-1.296
intercept_45
-0.143
intercept_56
0.886
intercept_67
2.009
n_factors
1
est_lgbtqYes
0.799
lowerCI_lgbtqYes
0.309
higherCI_lgbtqYes
1.289
se_lgbtqYes
0.249
tval_lgbtqYes
3.208
pval_lgbtqYes
0.001
# nationalitym_edi_issues_nat_null <-polr(assess_edi_issues_rating ~1, data=subset(survey, !is.na(nationality_continent)))m_edi_issues_nat <-polr(assess_edi_issues_rating ~ nationality_continent,data=survey) m_edi_issues_nat_out <-collect_out(model = m_edi_issues_nat, null = m_edi_issues_nat_null, name ="edi_issues_nat", n_factors =4, type ="likert", save ="yes", dir ="../results/survey") m_edi_issues_nat_out %>%t() %>%kbl() %>%kable_classic_2() # significant, North America higher
model_name
edi_issues_nat
AIC
1326.398
n_obs
371
lrt_pval
0.015
lrt_chisq
12.385
intercept_12
-3.45
intercept_23
-2.04
intercept_34
-1.405
intercept_45
-0.2
intercept_56
0.853
intercept_67
2.034
n_factors
4
est_nationality_continentAsia
-0.317
lowerCI_nationality_continentAsia
-0.951
higherCI_nationality_continentAsia
0.316
se_nationality_continentAsia
0.322
tval_nationality_continentAsia
-0.985
pval_nationality_continentAsia
0.325
est_nationality_continentNorth America
0.991
lowerCI_nationality_continentNorth America
0.338
higherCI_nationality_continentNorth America
1.644
se_nationality_continentNorth America
0.332
tval_nationality_continentNorth America
2.985
pval_nationality_continentNorth America
0.003
est_nationality_continentOceania
0.636
lowerCI_nationality_continentOceania
-0.577
higherCI_nationality_continentOceania
1.85
se_nationality_continentOceania
0.617
tval_nationality_continentOceania
1.032
pval_nationality_continentOceania
0.303
est_nationality_continentSouth America
0.715
lowerCI_nationality_continentSouth America
-0.581
higherCI_nationality_continentSouth America
2.01
se_nationality_continentSouth America
0.659
tval_nationality_continentSouth America
1.085
pval_nationality_continentSouth America
0.279
# affiliationm_edi_issues_aff_null <-polr(assess_edi_issues_rating ~1, data=subset(survey, !is.na(affiliation_continent)))m_edi_issues_aff <-polr(assess_edi_issues_rating ~ affiliation_continent,data=subset(survey, !is.na(affiliation_continent))) m_edi_issues_aff_out <-collect_out(model = m_edi_issues_aff, null = m_edi_issues_aff_null, name ="edi_issues_aff", n_factors =5, type ="likert", save ="yes", dir ="../results/survey") m_edi_issues_aff_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
edi_issues_aff
AIC
1344.82
n_obs
374
lrt_pval
0.238
lrt_chisq
6.775
intercept_12
-3.485
intercept_23
-2.079
intercept_34
-1.451
intercept_45
-0.276
intercept_56
0.773
intercept_67
1.919
n_factors
5
est_affiliation_continentAsia
0.264
lowerCI_affiliation_continentAsia
-0.684
higherCI_affiliation_continentAsia
1.212
se_affiliation_continentAsia
0.482
tval_affiliation_continentAsia
0.547
pval_affiliation_continentAsia
0.584
est_affiliation_continentAfrica
13.018
lowerCI_affiliation_continentAfrica
-492.568
higherCI_affiliation_continentAfrica
518.604
se_affiliation_continentAfrica
257.097
tval_affiliation_continentAfrica
0.051
pval_affiliation_continentAfrica
0.96
est_affiliation_continentNorth America
0.466
lowerCI_affiliation_continentNorth America
-0.342
higherCI_affiliation_continentNorth America
1.273
se_affiliation_continentNorth America
0.411
tval_affiliation_continentNorth America
1.134
pval_affiliation_continentNorth America
0.258
est_affiliation_continentOceania
-0.653
lowerCI_affiliation_continentOceania
-1.918
higherCI_affiliation_continentOceania
0.612
se_affiliation_continentOceania
0.643
tval_affiliation_continentOceania
-1.015
pval_affiliation_continentOceania
0.311
est_affiliation_continentSouth America
0.502
lowerCI_affiliation_continentSouth America
-2.923
higherCI_affiliation_continentSouth America
3.927
se_affiliation_continentSouth America
1.742
tval_affiliation_continentSouth America
0.288
pval_affiliation_continentSouth America
0.773
# expatm_edi_issues_expat_null <-polr(assess_edi_issues_rating ~1, data=subset(survey, !is.na(expat)))m_edi_issues_expat <-polr(assess_edi_issues_rating ~ expat,data=subset(survey, !is.na(expat))) m_edi_issues_expat_out <-collect_out(model = m_edi_issues_expat, null = m_edi_issues_expat_null, name ="edi_issues_expat", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_edi_issues_expat_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
edi_issues_expat
AIC
1312.628
n_obs
368
lrt_pval
0.003
lrt_chisq
8.881
intercept_12
-3.254
intercept_23
-1.851
intercept_34
-1.236
intercept_45
-0.029
intercept_56
1.03
intercept_67
2.19
n_factors
1
est_expatExpat
0.555
lowerCI_expatExpat
0.187
higherCI_expatExpat
0.923
se_expatExpat
0.187
tval_expatExpat
2.967
pval_expatExpat
0.003
# english level survey$english_comfort_rating <-as.numeric(as.character(survey$english_comfort_rating))m_edi_issues_english_null <-polr(assess_edi_issues_rating ~1, data=subset(survey, !is.na(english_comfort_rating)))m_edi_issues_english <-polr(assess_edi_issues_rating ~ english_comfort_rating,data=subset(survey, !is.na(english_comfort_rating))) m_edi_issues_english_out <-collect_out(model = m_edi_issues_english, null = m_edi_issues_english_null, name ="edi_issues_english", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_edi_issues_english_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
edi_issues_english
AIC
1373.653
n_obs
381
lrt_pval
0.583
lrt_chisq
0.301
intercept_12
-3.184
intercept_23
-1.757
intercept_34
-1.091
intercept_45
0.052
intercept_56
1.074
intercept_67
2.201
n_factors
1
est_english_comfort_rating
0.052
lowerCI_english_comfort_rating
-0.134
higherCI_english_comfort_rating
0.237
se_english_comfort_rating
0.094
tval_english_comfort_rating
0.547
pval_english_comfort_rating
0.585
# agem_edi_issues_age_null <-polr(assess_edi_issues_rating ~1, data=subset(survey, !is.na(age)))m_edi_issues_age <-polr(assess_edi_issues_rating ~ age,data=subset(survey, !is.na(age))) m_edi_issues_age_out <-collect_out(model = m_edi_issues_age, null = m_edi_issues_age_null, name ="edi_issues_age", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_edi_issues_age_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
edi_issues_age
AIC
1373.432
n_obs
381
lrt_pval
0.283
lrt_chisq
2.521
intercept_12
-3.577
intercept_23
-2.147
intercept_34
-1.477
intercept_45
-0.328
intercept_56
0.698
intercept_67
1.827
n_factors
2
est_age35-50
-0.01
lowerCI_age35-50
-0.406
higherCI_age35-50
0.386
se_age35-50
0.202
tval_age35-50
-0.05
pval_age35-50
0.96
est_age> 50
-0.518
lowerCI_age> 50
-1.168
higherCI_age> 50
0.132
se_age> 50
0.331
tval_age> 50
-1.567
pval_age> 50
0.118
### build final model only with significant variablesm_edi_issues_null <-polr(assess_edi_issues_rating ~1, data=subset(survey, !is.na(gender) &!is.na(lgbtq) &!is.na(nationality_continent) &!is.na(expat)))m_edi_issues <-polr(assess_edi_issues_rating ~ gender + lgbtq + nationality_continent + expat, data=subset(survey, !is.na(gender) &!is.na(lgbtq) &!is.na(nationality_continent) &!is.na(expat)))drop1(m_edi_issues, test ="Chisq") #gender not sig anymore
m_edi_issues_out <-collect_out(model = m_edi_issues, null = m_edi_issues_null, name ="edi_issues_final", n_factors =8, type ="likert", save ="yes", dir ="../results/survey") m_edi_issues_out %>%t() %>%kbl() %>%kable_classic_2()
model_name
edi_issues_final
AIC
1210.941
n_obs
342
lrt_pval
0
lrt_chisq
34.391
intercept_12
-2.876
intercept_23
-1.43
intercept_34
-0.771
intercept_45
0.488
intercept_56
1.6
intercept_67
2.768
n_factors
8
est_genderFemale
0.481
lowerCI_genderFemale
0.051
higherCI_genderFemale
0.911
se_genderFemale
0.219
tval_genderFemale
2.2
pval_genderFemale
0.029
est_genderNon-binary
0.238
lowerCI_genderNon-binary
-1.123
higherCI_genderNon-binary
1.599
se_genderNon-binary
0.692
tval_genderNon-binary
0.344
pval_genderNon-binary
0.731
est_lgbtqYes
0.729
lowerCI_lgbtqYes
0.185
higherCI_lgbtqYes
1.273
se_lgbtqYes
0.276
tval_lgbtqYes
2.637
pval_lgbtqYes
0.009
est_nationality_continentAsia
-0.335
lowerCI_nationality_continentAsia
-1.009
higherCI_nationality_continentAsia
0.339
se_nationality_continentAsia
0.343
tval_nationality_continentAsia
-0.978
pval_nationality_continentAsia
0.329
est_nationality_continentNorth America
0.767
lowerCI_nationality_continentNorth America
0.087
higherCI_nationality_continentNorth America
1.446
se_nationality_continentNorth America
0.345
tval_nationality_continentNorth America
2.219
pval_nationality_continentNorth America
0.027
est_nationality_continentOceania
0.368
lowerCI_nationality_continentOceania
-0.985
higherCI_nationality_continentOceania
1.721
se_nationality_continentOceania
0.688
tval_nationality_continentOceania
0.535
pval_nationality_continentOceania
0.593
est_nationality_continentSouth America
1.267
lowerCI_nationality_continentSouth America
-0.296
higherCI_nationality_continentSouth America
2.83
se_nationality_continentSouth America
0.795
tval_nationality_continentSouth America
1.594
pval_nationality_continentSouth America
0.112
est_expatExpat
0.548
lowerCI_expatExpat
0.158
higherCI_expatExpat
0.939
se_expatExpat
0.199
tval_expatExpat
2.762
pval_expatExpat
0.006
The results indicate that even though gender and nationality were significant in the univariate models, when accounting for LGBTQ+ identity and expat status, they are not significant anymore in the final model (although nationality is borderline significant). The final model shows that LGBTQ+ identities agree more with there being EDI issues in our field, and so do expats. Looking at nationality, the result is difficult to interpret due to the unbalanced sample size and needing to drop the nationality on a sub-continent level to zoom out to the continent level. Nevertheless, it appears that North American nationalities agrees more compared to European nationalities.
8.3 Question asking gender disparity
# first, we explore the distribution of answers# no qa disparityggplot(survey, aes(assess_gender_qa_rating)) +geom_histogram(stat="count", aes(y=stat(count/sum(count)*100)), fill = clrs[11]) +geom_text(aes(label =paste0("N = ", ..count..), y =stat(count/sum(count)*100)), stat="count", vjust=-1) +labs(x ="I think the questions asked after the talks were equally divided across genders", y ="% of responses")
# then we test the effect of each of the social identity variables# genderm_gender_qa_gender_null <-polr(assess_gender_qa_rating ~1, data=subset(survey, !is.na(gender)))m_gender_qa_gender <-polr(assess_gender_qa_rating ~ gender,data=survey) m_gender_qa_gender_out <-collect_out(model = m_gender_qa_gender, null = m_gender_qa_gender_null, name ="gender_qa_gender", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_gender_qa_gender_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
gender_qa_gender
AIC
1345.544
n_obs
373
lrt_pval
0.014
lrt_chisq
8.58
intercept_12
-3.343
intercept_23
-2.565
intercept_34
-1.651
intercept_45
-0.357
intercept_56
0.404
intercept_67
1.655
n_factors
2
est_genderFemale
-0.44
lowerCI_genderFemale
-0.836
higherCI_genderFemale
-0.043
se_genderFemale
0.202
tval_genderFemale
-2.181
pval_genderFemale
0.03
est_genderNon-binary
-1.516
lowerCI_genderNon-binary
-2.761
higherCI_genderNon-binary
-0.271
se_genderNon-binary
0.633
tval_genderNon-binary
-2.394
pval_genderNon-binary
0.017
# lgbtqia m_gender_qa_lgbtq_null <-polr(assess_gender_qa_rating ~1, data=subset(survey, !is.na(lgbtq)))m_gender_qa_lgbtq <-polr(assess_gender_qa_rating ~ lgbtq,data=subset(survey, !is.na(lgbtq))) m_gender_qa_lgbtq_out <-collect_out(model = m_gender_qa_lgbtq, null = m_gender_qa_lgbtq_null, name ="gender_qa_lgbtq", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_gender_qa_lgbtq_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
gender_qa_lgbtq
AIC
1295.149
n_obs
360
lrt_pval
0.006
lrt_chisq
7.599
intercept_12
-3.088
intercept_23
-2.364
intercept_34
-1.413
intercept_45
-0.105
intercept_56
0.649
intercept_67
1.875
n_factors
1
est_lgbtqYes
-0.692
lowerCI_lgbtqYes
-1.189
higherCI_lgbtqYes
-0.196
se_lgbtqYes
0.252
tval_lgbtqYes
-2.742
pval_lgbtqYes
0.006
# nationalitym_gender_qa_nat_null <-polr(assess_gender_qa_rating ~1, data=subset(survey, !is.na(nationality_continent)))m_gender_qa_nat <-polr(assess_gender_qa_rating ~ nationality_continent,data=survey) m_gender_qa_nat_out <-collect_out(model = m_gender_qa_nat, null = m_gender_qa_nat_null, name ="gender_qa_nat", n_factors =4, type ="likert", save ="yes", dir ="../results/survey") m_gender_qa_nat_out %>%t() %>%kbl() %>%kable_classic_2() # significant, Asia sig with higher values
model_name
gender_qa_nat
AIC
1345.941
n_obs
374
lrt_pval
0.011
lrt_chisq
13.085
intercept_12
-2.988
intercept_23
-2.152
intercept_34
-1.24
intercept_45
0.089
intercept_56
0.843
intercept_67
2.077
n_factors
4
est_nationality_continentAsia
1.126
lowerCI_nationality_continentAsia
0.456
higherCI_nationality_continentAsia
1.796
se_nationality_continentAsia
0.341
tval_nationality_continentAsia
3.304
pval_nationality_continentAsia
0.001
est_nationality_continentNorth America
-0.227
lowerCI_nationality_continentNorth America
-0.903
higherCI_nationality_continentNorth America
0.449
se_nationality_continentNorth America
0.344
tval_nationality_continentNorth America
-0.661
pval_nationality_continentNorth America
0.509
est_nationality_continentOceania
-0.081
lowerCI_nationality_continentOceania
-1.326
higherCI_nationality_continentOceania
1.165
se_nationality_continentOceania
0.633
tval_nationality_continentOceania
-0.127
pval_nationality_continentOceania
0.899
est_nationality_continentSouth America
0.936
lowerCI_nationality_continentSouth America
-0.692
higherCI_nationality_continentSouth America
2.563
se_nationality_continentSouth America
0.828
tval_nationality_continentSouth America
1.131
pval_nationality_continentSouth America
0.259
# affiliation m_gender_qa_aff_null <-polr(assess_gender_qa_rating ~1, data=subset(survey, !is.na(affiliation_continent)))m_gender_qa_aff <-polr(assess_gender_qa_rating ~ affiliation_continent,data=subset(survey, !is.na(affiliation_continent))) m_gender_qa_aff_out <-collect_out(model = m_gender_qa_aff, null = m_gender_qa_aff_null, name ="gender_qa_aff", n_factors =5, type ="likert", save ="yes", dir ="../results/survey") m_gender_qa_aff_out %>%t() %>%kbl() %>%kable_classic_2() #sig, South America almost sig with lower values
model_name
gender_qa_aff
AIC
1356.011
n_obs
377
lrt_pval
0.009
lrt_chisq
15.324
intercept_12
-2.992
intercept_23
-2.209
intercept_34
-1.279
intercept_45
0.044
intercept_56
0.809
intercept_67
2.079
n_factors
5
est_affiliation_continentAsia
1.615
lowerCI_affiliation_continentAsia
0.632
higherCI_affiliation_continentAsia
2.599
se_affiliation_continentAsia
0.5
tval_affiliation_continentAsia
3.231
pval_affiliation_continentAsia
0.001
est_affiliation_continentAfrica
1.444
lowerCI_affiliation_continentAfrica
-1.489
higherCI_affiliation_continentAfrica
4.377
se_affiliation_continentAfrica
1.491
tval_affiliation_continentAfrica
0.968
pval_affiliation_continentAfrica
0.334
est_affiliation_continentNorth America
-0.306
lowerCI_affiliation_continentNorth America
-1.117
higherCI_affiliation_continentNorth America
0.504
se_affiliation_continentNorth America
0.412
tval_affiliation_continentNorth America
-0.743
pval_affiliation_continentNorth America
0.458
est_affiliation_continentOceania
0.393
lowerCI_affiliation_continentOceania
-0.706
higherCI_affiliation_continentOceania
1.492
se_affiliation_continentOceania
0.559
tval_affiliation_continentOceania
0.703
pval_affiliation_continentOceania
0.483
est_affiliation_continentSouth America
-2.338
lowerCI_affiliation_continentSouth America
-5.152
higherCI_affiliation_continentSouth America
0.476
se_affiliation_continentSouth America
1.431
tval_affiliation_continentSouth America
-1.634
pval_affiliation_continentSouth America
0.103
# expatm_gender_qa_expat_null <-polr(assess_gender_qa_rating ~1, data=subset(survey, !is.na(expat)))m_gender_qa_expat <-polr(assess_gender_qa_rating ~ expat,data=subset(survey, !is.na(expat))) m_gender_qa_expat_out <-collect_out(model = m_gender_qa_expat, null = m_gender_qa_expat_null, name ="gender_qa_expat", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_gender_qa_expat_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
gender_qa_expat
AIC
1340.416
n_obs
371
lrt_pval
0.801
lrt_chisq
0.063
intercept_12
-3.058
intercept_23
-2.253
intercept_34
-1.329
intercept_45
-0.016
intercept_56
0.73
intercept_67
1.934
n_factors
1
est_expatExpat
-0.046
lowerCI_expatExpat
-0.409
higherCI_expatExpat
0.316
se_expatExpat
0.185
tval_expatExpat
-0.252
pval_expatExpat
0.801
# english level survey$english_comfort_rating <-as.numeric(as.character(survey$english_comfort_rating))m_gender_qa_english_null <-polr(assess_gender_qa_rating ~1, data=subset(survey, !is.na(english_comfort_rating)))m_gender_qa_english <-polr(assess_gender_qa_rating ~ english_comfort_rating,data=subset(survey, !is.na(english_comfort_rating))) m_gender_qa_english_out <-collect_out(model = m_gender_qa_english, null = m_gender_qa_english_null, name ="gender_qa_english", n_factors =1, type ="likert", save ="yes", dir ="../results/survey") m_gender_qa_english_out %>%t() %>%kbl() %>%kable_classic_2() # significant
model_name
gender_qa_english
AIC
1383.542
n_obs
384
lrt_pval
0.016
lrt_chisq
5.795
intercept_12
-4.497
intercept_23
-3.692
intercept_34
-2.781
intercept_45
-1.46
intercept_56
-0.711
intercept_67
0.501
n_factors
1
est_english_comfort_rating
-0.228
lowerCI_english_comfort_rating
-0.414
higherCI_english_comfort_rating
-0.042
se_english_comfort_rating
0.095
tval_english_comfort_rating
-2.411
pval_english_comfort_rating
0.016
# agem_gender_qa_age_null <-polr(assess_gender_qa_rating ~1, data=subset(survey, !is.na(age)))m_gender_qa_age <-polr(assess_gender_qa_rating ~ age,data=subset(survey, !is.na(age))) m_gender_qa_age_out <-collect_out(model = m_gender_qa_age, null = m_gender_qa_age_null, name ="gender_qa_age", n_factors =2, type ="likert", save ="yes", dir ="../results/survey") m_gender_qa_age_out %>%t() %>%kbl() %>%kable_classic_2() # not significant
model_name
gender_qa_age
AIC
1387.829
n_obs
384
lrt_pval
0.173
lrt_chisq
3.507
intercept_12
-3.16
intercept_23
-2.355
intercept_34
-1.448
intercept_45
-0.139
intercept_56
0.607
intercept_67
1.82
n_factors
2
est_age35-50
-0.316
lowerCI_age35-50
-0.71
higherCI_age35-50
0.079
se_age35-50
0.201
tval_age35-50
-1.571
pval_age35-50
0.117
est_age> 50
-0.419
lowerCI_age> 50
-1.037
higherCI_age> 50
0.198
se_age> 50
0.314
tval_age> 50
-1.336
pval_age> 50
0.182
### build final model only with significant variablesm_gender_qa_null <-polr(assess_gender_qa_rating ~1, data=subset(survey, !is.na(gender) &!is.na(lgbtq) &!is.na(nationality_continent) &!is.na(affiliation_continent) &!is.na(english_comfort_rating)))m_gender_qa <-polr(assess_gender_qa_rating ~ gender + lgbtq + nationality_continent + affiliation_continent + english_comfort_rating, data=subset(survey, !is.na(gender) &!is.na(lgbtq) &!is.na(nationality_continent) &!is.na(affiliation_continent) &!is.na(english_comfort_rating)))drop1(m_gender_qa, test ="Chisq") #gender not sig anymore, lgbtq and nationality borderline
m_gender_qa_out <-collect_out(model = m_gender_qa, null = m_gender_qa_null, name ="gender_qa_final", n_factors =13, type ="likert", save ="yes", dir ="../results/survey") m_gender_qa_out %>%t() %>%kbl() %>%kable_classic_2()
model_name
gender_qa_final
AIC
1234.907
n_obs
344
lrt_pval
0.001
lrt_chisq
36.286
intercept_12
-4.856
intercept_23
-4.087
intercept_34
-3.113
intercept_45
-1.768
intercept_56
-0.974
intercept_67
0.363
n_factors
13
est_genderFemale
-0.405
lowerCI_genderFemale
-0.847
higherCI_genderFemale
0.036
se_genderFemale
0.224
tval_genderFemale
-1.807
pval_genderFemale
0.072
est_genderNon-binary
-1.079
lowerCI_genderNon-binary
-2.448
higherCI_genderNon-binary
0.29
se_genderNon-binary
0.696
tval_genderNon-binary
-1.55
pval_genderNon-binary
0.122
est_lgbtqYes
-0.521
lowerCI_lgbtqYes
-1.09
higherCI_lgbtqYes
0.049
se_lgbtqYes
0.29
tval_lgbtqYes
-1.798
pval_lgbtqYes
0.073
est_nationality_continentAsia
0.742
lowerCI_nationality_continentAsia
-0.144
higherCI_nationality_continentAsia
1.629
se_nationality_continentAsia
0.451
tval_nationality_continentAsia
1.648
pval_nationality_continentAsia
0.1
est_nationality_continentNorth America
0.433
lowerCI_nationality_continentNorth America
-0.395
higherCI_nationality_continentNorth America
1.26
se_nationality_continentNorth America
0.421
tval_nationality_continentNorth America
1.029
pval_nationality_continentNorth America
0.304
est_nationality_continentOceania
-0.256
lowerCI_nationality_continentOceania
-1.96
higherCI_nationality_continentOceania
1.447
se_nationality_continentOceania
0.866
tval_nationality_continentOceania
-0.296
pval_nationality_continentOceania
0.768
est_nationality_continentSouth America
2.639
lowerCI_nationality_continentSouth America
0.094
higherCI_nationality_continentSouth America
5.184
se_nationality_continentSouth America
1.294
tval_nationality_continentSouth America
2.04
pval_nationality_continentSouth America
0.042
est_affiliation_continentAsia
0.575
lowerCI_affiliation_continentAsia
-0.786
higherCI_affiliation_continentAsia
1.936
se_affiliation_continentAsia
0.692
tval_affiliation_continentAsia
0.831
pval_affiliation_continentAsia
0.406
est_affiliation_continentAfrica
1.74
lowerCI_affiliation_continentAfrica
-1.22
higherCI_affiliation_continentAfrica
4.7
se_affiliation_continentAfrica
1.505
tval_affiliation_continentAfrica
1.156
pval_affiliation_continentAfrica
0.248
est_affiliation_continentNorth America
-0.448
lowerCI_affiliation_continentNorth America
-1.421
higherCI_affiliation_continentNorth America
0.526
se_affiliation_continentNorth America
0.495
tval_affiliation_continentNorth America
-0.905
pval_affiliation_continentNorth America
0.366
est_affiliation_continentOceania
0.53
lowerCI_affiliation_continentOceania
-1.007
higherCI_affiliation_continentOceania
2.068
se_affiliation_continentOceania
0.782
tval_affiliation_continentOceania
0.679
pval_affiliation_continentOceania
0.498
est_affiliation_continentSouth America
-5.387
lowerCI_affiliation_continentSouth America
-9.229
higherCI_affiliation_continentSouth America
-1.544
se_affiliation_continentSouth America
1.953
tval_affiliation_continentSouth America
-2.758
pval_affiliation_continentSouth America
0.006
est_english_comfort_rating
-0.234
lowerCI_english_comfort_rating
-0.441
higherCI_english_comfort_rating
-0.027
se_english_comfort_rating
0.105
tval_english_comfort_rating
-2.227
pval_english_comfort_rating
0.027
The results indicate that even though gender, LGBTQ+ and nationality were significant in the univariate models, when accounting for all other significant variables too, they are not significant anymore in the final model (although LGBTQ+ and nationality are borderline significant). The final model shows that Asian countries agree more compared to European nationalities. South American affiliates agree less compared to European affiliations. Lastly, people who are more comfortable speaking English agree less with the statement.
LGBTQ+ identities agree more with there being EDI issues in our field, and so do expats. Looking at nationality, the result is difficult to interpret due to the unbalanced sample size and needing to drop the nationality on a sub-continent level to zoom out to the continent level. Nevertheless, it appears that North American nationalities agrees more compared to European nationalities.